1. Scraping Engine
Packaging DeliveryEngine Monitor
Notification
Engine Properties
Configuration
Page Element
Configuration
Proxy Collector
Notification
Template
Event
Trigger
Property
Reader
Proxy
Claimer
Page Element
Reader
Page
Loader
Data
Processor
ScraperScraping
Case
DB
Web Scraping Solution
- ScrapeXpress Classic Solution Series -
Author: Andy Yang
Auditor:
Created Date: 13/10/2015
Last Updated: 13/10/2015
Version: 1.3
Dependency Document: BusinessRequirementOfWebScrapingForxxxx_v1.1.docx
1. overview
2. 2. Business Modules
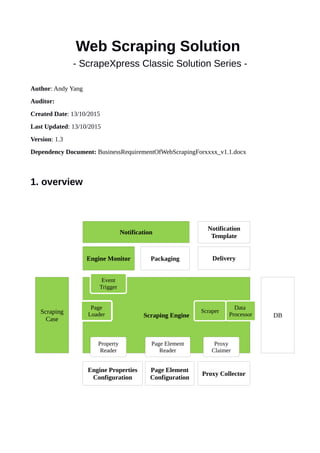
2.1. Core Module – Scraping Engine
Scraping Engine( also called Engine) - One Engine for one website
Execute a scraping task, scrape pre-defined data fields from web page and convert result
data into universal data object which is easy to be used by other modules, the module will invoke
other relevant modules to finish whole scraping task.
Components:
Engine Event Trigger
Create event and fire it to Engine Monitor
Engine Properties Reader
Read engine properties defined by Engine Properties Configuration
Proxy Claimer
Claim a proxy ip from Proxy Pool maintained by Proxy Collector
Page Elements Configuration Reader
Read and analyse the configuration of page elements defined by Page Element
Configuration
Page Content Loader
Accept the url request, retrieve and transform web page content into the stream of html
source code
Data Scraper
Parse html content and extract each data field from the stream of html source code by
invoking API of the third-party API, finally save these datas into universal data object.
Data Processor
Save data into database or forward to Packaging Module
Send notification to specified user by Notification Module
Output
Invoke Packaging Module to package result data into specified formatted file
Invoke Delivery Module to put packaged file into target folder
Fire exception event to Engine Monitor to handle these events.
Invoke Notification Module to notice the specific user (Finance DEPT) the status of
3. scraping task by email
Input
Read Engine Properties to control the engine running
Read Web Page Structure Configuration to scrape specified data from web page
content correctly
Dynamically claim a proxy IP and use it to access the target url.
2.2. Packaging Module
Accept the result data from Scraping Engine and convert data into formatted file, such as
EXCEL or CSV.
2.3. Delivery Module
Accept the delivery command from Scraping Engine and put packaged file into specified
folder.
Tips: This module can be extend to deliver data file by different way, such as by email.
2.4. Engine Monitor
Accept the exception event fired by Scraping Engine, generate the message content due to
the message template and invoke Notification Module to send message to ITD
2.5. Notification Module
According to the pre-defined method, accept message object and send message to specified
user by email.
3. Supporting Modules:
3.1. Engine Properties Configurator
Define the properties of Scraping Engine which will be used when Scraping Engine execute
a scraping task.
3.2. Page Element Configurator
Define the each data element that you want to scrape from web page
3.3. Proxy Collector
Collect free proxy server ip from online website, validate and submit available proxy ip into
Proxy Pool.
4. 3.4. Notification Template Management
Create and maintain the template of notification message, so that we can adjust the content
and format depending on the business scenario.
4. Scraping Case System
4.1. Scraping Case Builder
Define a Case
put the Page Element Configuration into java code
Initialise the data, such as search condition, running schedule...
4.2. Scraping Case Controller
Run, stop a running case or start
Log the status of scraping process.
5. Implement Strategy
We separate the whole progress of project into 3 stages:
1. Stage 1 : Basic Functions
2. Stage 2 : Support & Advance Functions
3. Stage 3: High Level Functions
Stage 1: Basic Functions
Scope
Develop essential modules and functions so that we can scrape data from 3 website
mentioned in requirement document, put some supporting modules and high level functions to stage
2 or stage 3.
Module Functions & Comment
Scraping Engine Engine Properties Reader :
only write the properties into java code instead of reading from config file
Reading properties from config file will be developed in stage 2;
Page Elements Configuration Reader:
only write the Page Element Configuration into java code instead of
reading from configuration file
5. Reading Page Element Configuration from config file will be
developed in stage 3;
Page Content Loader: Only directly access the target website instead of
via proxy server
via proxy server will be in stage2 or stage3
Proxy Claimer:
only define interface instead of claiming proxy ip from Proxy Pool
Claiming proxy ip from Proxy Pool will be in stage2
Engine Event Trigger:
Define essential events to be fired
According to the requirement, we will add new event in stage 2 and
stage 3.
Data Scraper:
Need invoke the third-side api to scrape data from web page according to
the Page Element Configuration instead of developing whole data
scraping algorithm.
We will rewrite the whole algorithm in stage 3
Data Processor:
Directly save data into database and package data into formatted file
Engine Monitor Able to these events fired by stage 2
Packaging Module Package data into Excel file and put it to specified folder
Notification Module Able to send essential notifications to ITD and Finance DEPT
Scraping Case
Builder
Create scraping case for 3 websites and initialise the search conditons;
put the Page Element Configuration into java code
Scraping Case
Controller
Provide start and stop functions to run scraping case to scraped data
no log functions
Workload Assessment of Stage 1
Jobs Work load (work day)
Preparation
1 Validate feasibility of technology
2 Prepare development environment and tools
3 Design and confirm data structure / definitions
6. Coding & Unit Testing
4 Program Scraping Engine
5 Program Engine Monitor
6 Program Packaging Module
6 Program Notification Module
Data Preparation
7 Collect search conditions from 2 websites:Divvy and
Parkhound
7 Create and initialise Scraping Case
8 Put the Page Element Configuration into java code
For 3 websites
Testing and Deployment
9 Build testing environment and testing
10 Build production environment and deploy system
Only run as standalone application
Maintenance and Document
11 On-site maintenance and fix bug
12 Write usage instructions
Not technology document
Stage 2: Support and Advance Functions
Module Functions & Comment
Scraping Engine Reading properties from config file
Access target web site via proxy server
Claiming proxy ip from Proxy Pool
Engine Monitor Update depending on real requirements
Notification Module Update depending on real requirements
Scraping Case
Controller
Update depending on real requirements
Engine Properties
Configurator
Maintain the properties of engine into config file or table
Proxy Collector Manually write proxy list into Proxy Pool
Scraping Case
Controller
Log the status of scraping process.
7. Stage 3: High Level Functions
Module Functions & Comment
Scraping Engine Read Page Element Configuration from config file or table
Rewrite the whole algorithm of scraping data depending on the Page
Element Configuration.
Page Element
configurator
Proxy Collector Automatically collect proxy ip from internet website, validate the
connectivity of proxy ips
Notification Template
Management
Define the template of message out of the system instead of writing
message content in java code.