Jisc Vision for Improving OA Discovery
•Download as PPTX, PDF•
1 like•408 views

Jisc provides several services to support open access discovery and monitoring in the UK. However, a large proportion of open access material is still difficult to find due to issues with messy, lossy, expensive, and unreliable discovery. Improving the use of persistent identifiers across repositories, publishers, and funders could help create a more sustainable and comprehensive system for discovering open access content globally. This would better support finding, reusing, and measuring the impact of publicly available scholarship.

Recommended
Recommended
More Related Content
Similar to Jisc Vision for Improving OA Discovery
Similar to Jisc Vision for Improving OA Discovery (20)
More from Jisc
More from Jisc (20)
Recently uploaded
Recently uploaded (20)
Jisc Vision for Improving OA Discovery
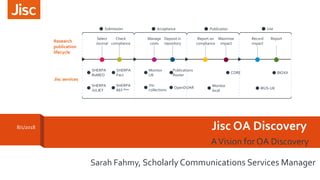
- 1. Jisc OA Discovery AVision for OA Discovery Submission Acceptance Publication Use SHERPA JULIET SHERPA RoMEO SHERPA REF Beta SHERPA Fact Monitor UK Jisc collections OpenDOAR Research publication lifecycle Jisc services Report on compliance Deposit in repository Manage costs Check compliance Select Journal Maximise impact Record impact Publications Router Report Monitor local CORE IRUS-UK RIOXX Sarah Fahmy, Scholarly Communications Services Manager 8/1/2018
- 2. Introduction »OA discovery is rapidly evolving area »Jisc is looking at ways in which it can improve OA discovery ‘on the ground’: › Potential improvements to current Jisc services (CORE) › Whether/ how we might engage in the future with existing OA Discovery tools
- 3. A vision for OA discovery »However, given that we do already have a thriving market place and given Jisc’s wider remit, potentially our role should be: › to address the underlying infrastructure that all discovery services rest on › … and so lower the common barriers to better OA discovery › … so what does this mean?
- 4. ‘The Universe of articles’ Credit: Robert Sullivan/ Public Domain licence: http://bit.ly/2DreAZ7 The entire body of research literature is currently estimated at over 100 million publications (Khabsa & Giles, 2014) … …with an estimated 10% year on year increase in the annual number of these outputs (Bornmann & Mutz, 2014)
- 5. Proportion of OA » The State of OA (Piwowar & Priem,2017) study looked across of 100,000 articles, to investigate OA in three populations: › All journal articles assigned a Crossref DOI › Recent journal articles indexed in Web of Science › Articles viewed by users of Unpaywall Findings: • Of 67mill articles Unpaywall searches across, 28% of the scholarly literature is OA (19M in total) • The most recent year analysed (2015) also has the highest percentage of OA (45%), which has almost certainly increased by 2018 So…OA is a significant success, and is now becoming the mainstream in many areas of research
- 6. OA Discovery:The conundrum Proportion of OA articles ‘Universe’ of ALL articles Think of it as a fraction…
- 7. » In many ways, we’re well served in terms of OA discovery services › Great deal of very agile innovation (Unpaywall, OAButton, Kopernio) › More established public infrastructure (OpenAIRE, CORE) › Well-used library discovery services (Primo, Summon, Ebsco, OCLC) › Long-standing commercial services (Web of Science, Scopus, Google Scholar). BUT.. Despite the objective of OA being to enable material to be more easily found, re-used and impactful (and the rationale for the considerable investment in it)…. OA Discovery Landscape
- 8. OA Discovery Landscape THERE IS STILL A LARGE PROPORTION OF OA MATERIALTHAT CAN’T BE EASILY FOUND (it’s the old adage..) CC BY-NC-ND 2.0, Credit: Andy Sim: https://bit.ly/2GWcB2w
- 10. The problem (2) Messy, lossy, expensive and unreliable
- 11. » Messy: the user experience is poor. Scholars and others interested in using public scholarship miss out on material that should be available to them. » Lossy: none of the discovery services is, or could possibly be, comprehensive. » Expensive: each discovery service has to spend time and money repeating and maintaining the exploration and harvesting work done by all the others » Unreliable: the same search of the same content can deliver different results day to day What do we mean by that?
- 12. How can we improve this situation? Improved use of persistent identifiers
- 13. What might those interventions be? Everyone to contribute to, and benefit from, the PID commons. Examples: 1. Repositories register PIDs for content they hold. Where relevant, link to journal DOIs, DataCite DOIs, etc 2. Publishers register a DOI at acceptance, using Crossref guidance on how to do this when no article is yet available 3. Funders take ownership of the development of a global research project identifier registry, to ensure it is community-governed 4. Everyone require ORCIDs and use the ORCID API…
- 14. The Outcome? A sustainable and significant improvement in the extent to which OA content globally can be found, re-used and make a difference..
- 15. PIDVision 15 » Mapping the Persistent Identifier landscape › PIDVision https://orcid.org/blog/2018/06/07/mapping-pid- landscape › Nature article https://www.nature.com/articles/d41586-018-05456- 8 › PID campaign – launching soon Contact community@orcid.org if you’d like to get involved.
- 16. Thank you for listening Any questions?
- 17. jisc.ac.uk Sarah Fahmy Scholarly Communications services manager sarah.fahmy@jisc.ac.uk 8/1/2018 AT2OA conference- Jisc OA Dashboard
Editor's Notes
- Using Crossref will give you a pretty good estimate of this number (excepting articles that don’t have a DOI, but these aren’t a huge number). But if you want to drill down by country or institution, Crossref currently doesn’t have enough affiliations or ORCIDs to do this with any accuracy.
- For the denominator (number of articles): using Crossref will give you a pretty good estimate of this number (excepting articles that don’t have a DOI, but these aren’t a huge number). But if you want to drill down by country or institution, Crossref currently doesn’t have enough affiliations or ORCIDs to do this with any accuracy. For the numerator (number of OA articles): Licence information is being filled in spottily, so the best you can do is get a lower bound for the number of OA articles (those that have an open licence in Crossref), with no way to accurately estimate the upper bound.
- 1. Completeness: All of these services are attempting to find OA scholarly material from a variety of places in which it might reside, each of which has its strengths and weaknesses as sources, making the job of those services rather difficult. Reliant on accuracy of the metadata- for example, we know licence information is being applied spottily so it’s hard to determine it OA status 2. Business models: A range of commercial, public and other business models co-exist for discovery services. Up to now the market has been the decider, but long-term sustainability for these services is a key issue
- Need to stress very strongly that this is purely illustrative, in no way meant to be an accurate description of the landscape
- We propose that a huge amount could be achieved through a programme of interventions that led to persistent identifiers being used better. “Persistent identifiers (DOIs, ORCIDs, ISBNs, etc) are the signposts in the research landscape and act as coordinates on the research map. They both tell us where something is located, and also act as signposts, guiding us to information sources and helping us to discover connections between people, ideas, organisations, funding, employment, publications, activities, and more.” Where they are used well, then OA discovery is relatively easy - anyone can build a service that uses the Crossref API. However, PIDs are not always used well, and often are not used at all. This is for a variety of reasons, but most of which are tractable via a combination of technical, cultural and organisational interventions within different stakeholder groups.