OpenNMT
•Download as PPTX, PDF•
3 likes•1,531 views

Brief introduction of OpenNMT: Open Source Neural Machine Translation in Torch.

Recommended
More Related Content
What's hot
Similar to OpenNMT
Similar to OpenNMT (20)
Recently uploaded
Recently uploaded (20)
OpenNMT
- 1. OpenNMT Open-Source Neural Machine Translation in Torch
- 2. What is OpenNMT? OpenNMT was originally developed by Yoon Kim and harvardnlp. Major source contributions and support come from SYSTRAN. Basically it is: “A Modularized Translation Program using Seq2Seq Attention Model”
- 3. Features of OpenNMT Simple general-purpose interface, requires only source/target files. Speed and memory optimizations for high-performance multi-GPU training. Includes a dependency-free C++ translator for model deployment. Latest research features to improve translation performance. Pretrained models available for several language pairs. Extensions to allow other sequence generation tasks such as summarization and image-to-text generation. Active open community welcoming both academic and industrial requests and contributions.
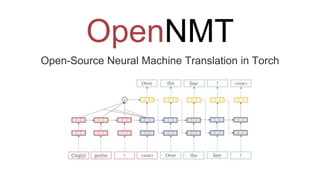
- 4. Model Encoder-Decoder LSTM The combination of context vector Compute the probability of the next token by computing affine transformation and softmax
- 7. Example Systran picked this phrase to show the superiority of their system. “I am officially running … for president of the United States, and we are going to make our country great again.” Notice the understanding the meaning of ‘running’ requires the context of the whole sentence. OpenNMT Demo: Korean - 저는 공식적으로 미국 대통령에 입후보하고 있으며, 우리는 우리 나라를 다시 위대하게 만들 것입니다. Chinese - 我是在正式竞选美国总统,我们将再次使我国伟大。 Google Translate: Korean - 나는 공식적으로 미국 대통령을 위해 달리고있다. 그리고 우리는 다시 우리나라를 위대하게 만들 것이다. Chinese - 我正式运行......为美国总统,我们将使我们的国家再次大。 Naver Translate: English to Korean - 나는 미국의 대통령을 공식적으로 운영하고 있으며, 우리 나라를 다시 위대하게 만들 것이다. Korean to English - I am officially running for president of the United States, and we will make our country great again.
- 8. Noticed it is not too difficult to write OpenNMT clone in Python if you use Tensorflow. Many of the functionalities in OpenNMT are already implemented in Tensorflow. Plan 1: Modularize the Tensorflow Seq2Seq example and add some convenient tools. Plan 2: Make this as a console application. As a new side project, we plan to publish this project by the end of the winter break (Jan 23) Contribute to OpenNMT? or publish a new Open Source? https://github.com/keonkim/OpenNMT OpenNMT in Python
Editor's Notes
- We propose two encoder-decoder architectures for this task. Our word-based architecture (WORD) is similar to that of Luong et al. (2015). Context vector The context vector is combined with the decoder hidden state through a one layer MLP (yellow), after which an affine transformation followed by a softmax is applied to obtain a distribution over the next word/tag Here, we model the probability of the target given the source, p(t | s), with an encoder neural network that summarizes the source sequence and a decoder neural network that generates a distribution over the target words and tags at each step given the source.
- FeaturesEmbedding --[[ A nngraph unit that maps features ids to embeddings. When using multiple features this can be the concatenation or the sum of each individual embedding. ]] FeaturesGenerator --[[ Feature decoder generator. Given RNN state, produce categorical distribution over tokens and features. Implements $$[softmax(W^1 h + b^1), softmax(W^2 h + b^2), ..., softmax(W^n h + b^n)] $$. --]] GLobalAttention The current target hidden state h_j is combined with each of the memory vectors in the source to produce attention weights. --[[ Global attention takes a matrix and a query vector. It then computes a parameterized convex combination of the matrix based on the input query to computer context vector. H_1 H_2 H_3 ... H_n q q q q | | | | \ | | / ..... \ | / a Constructs a unit mapping: $$(H_1 .. H_n, q) => (a)$$ Where H is of `batch x n x dim` and q is of `batch x dim`. The full function is $$\tanh(W_2 [(softmax((W_1 q + b_1) H) H), q] + b_2)$$. --]]