
Recommended
More Related Content
What's hot
What's hot (20)
Recently uploaded
Recently uploaded (20)
Yolov5
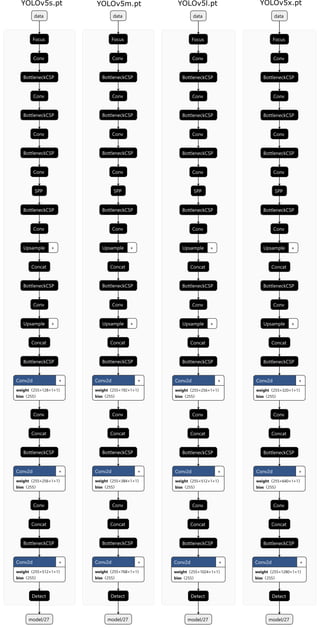
- 1. Focus Conv BottleneckCSP Conv BottleneckCSP Conv BottleneckCSP Conv SPP BottleneckCSP Conv Upsample + Concat BottleneckCSP Conv Upsample + Concat BottleneckCSP Conv2d + weight〈255×320×1×1〉 bias〈255〉 Conv Concat BottleneckCSP Conv2d + weight〈255×640×1×1〉 bias〈255〉 Conv Concat BottleneckCSP Conv2d + weight〈255×1280×1×1〉 bias〈255〉 Detect data model/27 Focus Conv BottleneckCSP Conv BottleneckCSP Conv BottleneckCSP Conv SPP BottleneckCSP Conv Upsample + Concat BottleneckCSP Conv Upsample + Concat BottleneckCSP Conv2d + weight〈255×256×1×1〉 bias〈255〉 Conv Concat BottleneckCSP Conv2d + weight〈255×512×1×1〉 bias〈255〉 Conv Concat BottleneckCSP Conv2d + weight〈255×1024×1×1〉 bias〈255〉 Detect data model/27 Focus Conv BottleneckCSP Conv BottleneckCSP Conv BottleneckCSP Conv SPP BottleneckCSP Conv Upsample + Concat BottleneckCSP Conv Upsample + Concat BottleneckCSP Conv2d + weight〈255×192×1×1〉 bias〈255〉 Conv Concat BottleneckCSP Conv2d + weight〈255×384×1×1〉 bias〈255〉 Conv Concat BottleneckCSP Conv2d + weight〈255×768×1×1〉 bias〈255〉 Detect data model/27 Focus Conv BottleneckCSP Conv BottleneckCSP Conv BottleneckCSP Conv SPP BottleneckCSP Conv Upsample + Concat BottleneckCSP Conv Upsample + Concat BottleneckCSP Conv2d + weight〈255×128×1×1〉 bias〈255〉 Conv Concat BottleneckCSP Conv2d + weight〈255×256×1×1〉 bias〈255〉 Conv Concat BottleneckCSP Conv2d + weight〈255×512×1×1〉 bias〈255〉 Detect data model/27 YOLOv5s.pt YOLOv5m.pt YOLOv5l.pt YOLOv5x.pt