Explorative Datenanalyse
•
3 likes•6,665 views

Foliensatz meiner Statistik-Vorlesung aus dem Sommersemester 2006 an der HS Harz

Recommended
More Related Content
What's hot
What's hot (20)
More from Christian Reinboth
More from Christian Reinboth (20)
Explorative Datenanalyse
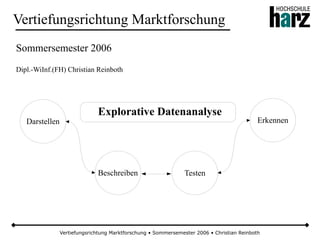
- 1. Vertiefungsrichtung Marktforschung • Sommersemester 2006 • Christian Reinboth Vertiefungsrichtung Marktforschung Sommersemester 2006 Dipl.-WiInf.(FH) Christian Reinboth Explorative Datenanalyse TestenBeschreiben Darstellen Erkennen
- 2. Vertiefungsrichtung Marktforschung • Sommersemester 2006 • Christian Reinboth Inhalte: Explorative Datenanalyse ● Wir unterscheiden in... ● Deskriptive Statistik (Beschreibung und Visualisierung der Daten) ● Explorative Statistik (Suchen nach Strukturen und Auffälligkeiten) ● Induktive Statistik (Testen von Hypothesen und Schätzen von Parametern) ● Fragestellung: Was ist an der Verteilung eines Merkmals bemerkenswert? ● Was gehört zur explorativen Datenanalyse? ● Berechnung statistischer Maßzahlen ● Darstellung absoluter und relativer Häufigkeiten ● Visualisierung diskreter und stetiger Variablen ● Analyse von Ausreißern ● Analyse fehlender Daten ● Transformation von Daten ● Erstellung von Dummy-Variablen ● Prüfung der Voraussetzungen für weiterführende Analysemethoden
- 3. Vertiefungsrichtung Marktforschung • Sommersemester 2006 • Christian Reinboth Inhalte: Explorative Datenanalyse ● Zu Beginn einer Datenanalyse... ● Lagemaße / Maße der zentralen Tendenz ● Das arithmetische Mittel ● Der Median ● Die Perzentilwerte ● Der Modus ● Streuungsmaße / Dispersionsparameter ● Die Spannweite ● Der Interquartilsabstand ● Varianz & Standardabweichung ● Grafische Darstellungsmöglichkeiten ● Säulen- und Balkendiagramme ● Kreisdiagramme ● Histogramme ● Stem-and-Leaf-Plots ● Box-Plots ● P-P-Diagramme ● Q-Q-Diagramme ● Streudiagramme ● Streudiagramm-Matritzen ● Ausreißeranalyse ● Ursachen für Ausreißer ● Identifikation von Ausreißern ● Leverage-Effekt ● Umgang mit Ausreißern ● Fehlende Daten ● Gründe für fehlende Daten ● Struktur fehlender Daten ● Umgang mit fehlenden Daten ● Prüfung von Voraussetzungen ● Prüfung auf Normalverteilung ● Prüfung auf Homoskedastizität ● Prüfung auf Linearität ● Arbeit mit Dummy-Variablen
- 4. Vertiefungsrichtung Marktforschung • Sommersemester 2006 • Christian Reinboth Zu Beginn einer Datenanalyse... ● ...ist es sinnvoll, einen Überblick über die vorliegenden Daten zu bekommen ● Darstellung von Lage und Verteilung der Werte – gibt es Auffälligkeiten in den Daten? ● Lagemaße: arithmetisches Mittel, Median, Perzentile, Modus ● Streumaße: Spannweite, Interquartilsabstand, Varianz, Standardabweichung ● Grafische Darstellung: Balken-, Kreis-, Stabdiagramm, Stem-and-Leaf, Histogramm, Box-Plot... ● Lassen sich extrem große oder kleine Werte (Ausreißer) in den Daten identifizieren? ● Sind außergewöhnliche Umstände oder Fehler die Ursache? ● Verzerren die Ausreißer die Ergebnisse der Datenanalyse? ● Ist es möglich, sie aus der weiteren Analyse auszuschließen? ● Erfüllen die vorliegenden Daten alle Voraussetzungen für weiterführende Analyseverfahren? ● Liegt eine Normalverteilung vor? ● Liegt eine Gleichheit der Varianzen vor? (Homoskedastizität) ● Welche Tests und Untersuchungen in eine solche explorative Datenanalyse gehören, ist nicht definitiv festgelegt ● Je nach der Art der Daten sowie der nachfolgenden Verfahren sind geeignete Teilelemente auszuwählen
- 5. Vertiefungsrichtung Marktforschung • Sommersemester 2006 • Christian Reinboth Lagemaße: Das arithmetische Mittel ● Das arithmetische Mittel ist das bekannteste statistische Lagemaß (Standardmittelwert) ● Es kann nur für metrisch skalierte Daten berechnet werden (Intervallskala, Verhältnisskala) ● Vorsicht: SPSS „berechnet“ das arithmetische Mittel auch für nichtmetrische Daten (Schulnoten!) ● Methodenkenntnisse des Anwenders sind daher erforderlich! ● Liegen von einem metrischen Merkmal x insgesamt n Werte vor, berechnet sich das arithmetische Mittel durch: ● Die Gesamtsumme aller Abweichungen von arithmetischen Mittel beträgt daher stets Null ● Das arithmetische Mittel ist nicht robust, d.h. sehr empfindlich gegenüber Ausreißern ● Beispiel: 1, 2, 3, 4 > (1+2+3+4) / 4 = 2,5 >>> 1, 2, 3, 50 > (1+2+3+50) / 4 = 14 x= 1 n ∑ i=1 n xi
- 6. Vertiefungsrichtung Marktforschung • Sommersemester 2006 • Christian Reinboth Weltweite Lebenserwartung
- 7. Vertiefungsrichtung Marktforschung • Sommersemester 2006 • Christian Reinboth Lagemaße: Der Median ● Der Median ist der Wert, der in der Mitte der geordneten Verteilung liegt ● Die Berechnung des Medians setzt mindestens ordinalskalierte Daten voraus ● Bei einer ungeraden Anzahl an Werten, wird der mittlere Wert gewählt: ● Bei einer geraden Anzahl an Werten wird das arithmetischen Mittel der beiden zentralen Werte gewählt: ● Bei klassierten Daten wird der mittlere Fall der zentralen Klasse ermittelt (unter Annahme einer Gleichverteilung) ● Der Median ist äußerst robust, d.h. er wird von Ausreißern nicht beeinflusst ● Aus diesem Grund ist er in der Regel aussagekräftiger als das arithmetische Mittel ● Beispiel: 1, 2, 3, 4, 5 > Median: 3 >>> 1, 2, 3, 4, 50 > Median: 3 xmed = xn1 2 xmed = 1 2 x n 2 x n 2 1
- 8. Vertiefungsrichtung Marktforschung • Sommersemester 2006 • Christian Reinboth Lagemaße: Perzentilwerte ● Perzentilwerte sind Werte, unterhalb derer ein eindeutig definierter Anteil aller Werte liegt ● Für die Berechnung der Perzentile müssen mindestens ordinalskalierte Daten vorliegen (geordnet) ● Der bekannteste Perzentilwert ist das 50%-Perzentil, welches auch als Median bezeichnet wird ● Häufig verwendet wird auch die „Vierteilung“ des Wertebereichs mit den sogenannten Quartilen: ● 25%-Perzentil (25% aller Werte liegen unterhalb dieses Wertes) ● 50%-Perzentil, Median (50% aller Werte liegen unter- bzw. oberhalb dieses Wertes) ● 75%-Perzentil (75% aller Werte liegen unterhalb dieses Wertes) ● Ebenso wie der Median, sind die Perzentile absolut robust, d.h. von Ausreißern nicht zu beeinflussen
- 9. Vertiefungsrichtung Marktforschung • Sommersemester 2006 • Christian Reinboth Lagemaße: Der Modus ● Der Modus (Modalwert) ist der in den vorliegenden Daten am häufigsten auftretende Wert ● Bei klassierten Daten ist der Modus die Klassenmitte der Klasse mit den meisten Fällen (nur gleichbreite Klassen) ● Die Berechnung des Modus ist in der Regel nur bei diskreten Daten sinnvoll (Punktwahrscheinlichkeit) ● Er wird insbesondere für nominalskalierte Merkmale gebildet, da hier kein anderes Lagemaß möglich ist ● Bei metrisch skalierten Daten können gleichbreite Klassen gebildet und darüber der Modus ermittelt werden ● Vorteil: Der Modus ist auch ohne Berechnung erkennbar und kann daher in der Praxis schnell bestimmt werden ● Nachteil: Der Modus kann nur eindeutig interpretiert werden, wenn ein einzelnes, klares Maximum vorliegt ● Sind mehrere Werte mit gleicher Häufigkeit vertreten, gibt SPSS den in der Häufigkeitstabelle zuoberst stehenden Wert an
- 10. Vertiefungsrichtung Marktforschung • Sommersemester 2006 • Christian Reinboth Lagemaße: Skalenniveaus & Interpretation Lagemaß Minimales Skalenniveau Modalwert Nominalskalenniveau Median / Perzentile Ordinalskalenniveau Arithmetisches Mittel Metrisches Skalenniveau Verhältnis der Lagemaße Verteilungsform Symmetrische Verteilung Linkssteile Verteilung Rechtssteile Verteilung x≈xmed≈xmod xxmedxmod xxmedxmod
- 11. Vertiefungsrichtung Marktforschung • Sommersemester 2006 • Christian Reinboth Streuungsmaße: Die Spannweite ● Die Spannweite ist der Abstand zwischen dem kleinsten (Minimum) und dem größten (Maximum) Wert im Datensatz ● Die Spannweite ist als Streuungsmaß ungenügend, da sie extrem stark von Ausreißern beeinflusst wird ● Existieren an beiden Verteilungsrändern Ausreißer, wird die Spannweite nur(!) durch diese bestimmt ● Beispiel: 1, 2, 3, 4, 5 > Spannweite: 4 >>> 1, 2, 3, 4, 50 > Spannweite: 49
- 12. Vertiefungsrichtung Marktforschung • Sommersemester 2006 • Christian Reinboth Streuungsmaße: Der Interquartilsabstand ● Der Interquartilsabstand (IQR = Inter Quartile Range) ist der Abstand zwischen dem oberen und dem unteren Quartil ● Da die beiden Quartile nicht von Ausreißern beeinflusst werden können, ist der IQR deutlich robuster als die Spannweite ● Aus den Quartilen sowie Minimum und Maximum lässt sich die kompakte 5-Werte-Zusammenfassung bilden Interquartilsabstand
- 13. Vertiefungsrichtung Marktforschung • Sommersemester 2006 • Christian Reinboth Streuungsmaße: Die Varianz ● Die Varianz (bzw. Standardabweichung) ist das gebräuchlichste Streuungsmaß ● Sie berechnet sich als Summe der quadrierten Abweichungen der Einzelwerte (Ausgleich negativer und positiver Abweichungen) vom arithmetischen Mittel, geteilt durch die Gesamtzahl aller Werte ● Bei der Berechnung der Stichproben-Varianz (SPSS) stehen die Freiheitsgrade im Nenner: ● Die Varianz wird kleiner, je näher die Einzelwerte am arithmetischen Mittel liegen ● Sind alle Werte mit dem Mittel identisch (keine Streuung), ergibt sich eine Varianz von Null ● Bei der Interpretation des Ergebnisses ist zu beachten, dass die quadrierten Werte in die Berechnung eingehen ● Dies hat zur Folge, dass auch die Varianz in der quadrierten Einheit dimensioniert ist (also z.B. in €² statt in €) ● Zur besseren Interpretation wird häufig die Standardabweichung als Quadratwurzel der Varianz angegeben S 2 = 1 N −1 ∑ i=1 N X i− X 2
- 14. Vertiefungsrichtung Marktforschung • Sommersemester 2006 • Christian Reinboth Grafische Darstellung univariater Daten Darstellungsformen ● Diskrete Merkmale ● Wenig Ausprägungen ● Stetige Merkmale ● Viele Ausprägungen Stabdiagramm Säulendiagramm Balkendiagramm Kreisdiagramm Stem & Leaf Histogramm Box-Plot Q-Q-Diagramm
- 15. Vertiefungsrichtung Marktforschung • Sommersemester 2006 • Christian Reinboth Grafik: Säulen- und Balkendiagramme ● Säulen- und Balkendiagramme eigenen sich primär für diskrete Merkmale mit einer geringen Anzahl an Ausprägungen ● Stetige Merkmale müssen vor der Darstellung klassiert werden, damit diese interpretierbar wird ● SPSS ermöglicht die grafische Darstellung sowohl der absoluten als auch der relativen Häufigkeiten im Diagramm
- 16. Vertiefungsrichtung Marktforschung • Sommersemester 2006 • Christian Reinboth Grafik: Kreisdiagramme ● Ebenso wie Säulen- und Balkendiagramme sind Kreisdiagramme primär für diskrete Merkmalsverteilungen geeignet ● Bei stetigen Merkmalen ist eine Klassierung für die grafische Darstellung unbedingt erforderlich
- 17. Vertiefungsrichtung Marktforschung • Sommersemester 2006 • Christian Reinboth Grafik: Histogramme ● Ein Histogramm stellt die Häufigkeitsverteilung der Werte einer intervallskalierten Variablen dar ● Dabei wird von nach der Größe geordneten Daten ausgegangen, die in n Klassen aufgeteilt werden, welche theoretisch nicht die gleiche Breite besitzen müssen (SPSS erstellt Histogramme stets mit gleichbreiten Klassen) ● Über jeder Klasse wird ein Rechteck konstruiert, dessen Flächeninhalt sich proportional zur absoluten bzw. relativen Häufigkeit der jeweiligen Klasse verhält (je nach Anlage des Histogramms) ● Die Form der Darstellung eignet sich primär für stetige Merkmale mit einer großen Anzahl an Ausprägungen ● Bei der Erstellung von Histogrammen mit SPSS ist zu beachten, dass maximal 21 Klassen gebildet werden können ● Außerdem kann eine Normalverteilungskurve in das Histogramm eingeblendet werden, aus der abgelesen werden kann, wie eine Normalverteilung bei Daten mit gleichem Mittelwert und gleicher Streuung aussehen würde (Voraussetzungsprüfung)
- 18. Vertiefungsrichtung Marktforschung • Sommersemester 2006 • Christian Reinboth Grafik: Stem-and-Leaf-Plots ● Stem-and-Leaf-Plots (Stamm-Blatt-Diagramme) eignen sich ebenfalls zur Darstellung stetiger Merkmale ● Der große Vorteil gegenüber jeder anderen grafischen Darstellungsform ist, dass die Originaldaten (bis zu einer gewissen Genauigkeit) noch aus dem Diagramm abgelesen werden können ● Das Diagramm ist ähnlich aufgebaut wie ein seitlich gekipptes Histogramm, d.h. flächenproportional ● Der Stamm besteht in der Regel aus der ersten Ziffer, die Blätter aus der jeweils folgenden (Rundungen) ● Sehr große oder sehr kleine Zahlen können auf- bzw. abgerundet oder als Extremwerte ausgewiesen werden ● Stem-and-Leaf-Plots können auch genutzt werden, um zwei Verteilungen miteinander zu vergleichen 1 | 1 1 1 2 2 3 4 5 7 7 2 | 2 2 4 3 | 3 3 3 4 5 8 8 4 | 1 2 9 9 9 9 2 Extremes Stem width: 10 Each leaf: 1 case(s) Datensatz A Datensatz B 8 8 8 3 2 | 1 | 1 1 1 2 2 3 4 5 7 7 2 1 | 2 | 2 2 4 9 5 4 4 3 3 | 3 | 3 3 3 4 5 8 8 4 3 3 2 1 | 4 | 1 2 9 9 9 9 3 Extremes 2 Extremes Stem width: 10 Each leaf: 1 case(s)
- 19. Vertiefungsrichtung Marktforschung • Sommersemester 2006 • Christian Reinboth Grafik: Box-Plots ● Box-Plots bieten einen direkten Verteilungsüberblick und eignen sich insbesondere zum Verteilungsvergleich ● Sie stellen sowohl Lage als auch Streuung der Verteilung dar und dienen zudem der Identifikation von Ausreißern Median Unteres Quartil Oberes Quartil * Ausreißer Extremer Wert Ausreißer Kleinster nicht-extremer Wert Größter nicht-extremer Wert 27 16 42 IQR4 IQR7 IQR
- 20. Vertiefungsrichtung Marktforschung • Sommersemester 2006 • Christian Reinboth Grafik: Box-Plots ● Aus der Lage des Medians innerhalb eines Box-Plots läßt sich die Form der Verteilung ablesen Symmetrische Verteilung Linkssteile Verteilung Rechtssteile Verteilung
- 21. Vertiefungsrichtung Marktforschung • Sommersemester 2006 • Christian Reinboth Grafik: Box-Plots ● Sollen mehrere Verteilungen bzw. mehrere überschneidungsfreie Gruppen (beispielsweise männliche und weibliche Angestellte) innerhalb einer Verteilung miteinander verglichen werden, lassen sich Box-Plots nebeneinander darstellen ● Weitergehende Vergleiche sind über gruppierte Box-Plots möglich, d.h. es erfolgt eine Aufteilung anhand mehr als nur eines Merkmals (beispielsweise anhand des Geschlechts und des Minderheitenstatus, wodurch sich vier Gruppen ergeben)
- 22. Vertiefungsrichtung Marktforschung • Sommersemester 2006 • Christian Reinboth Grafik: P-P-Diagramme ● Ein P-P-Diagramm trägt die kumulierten Häufigkeiten der beobachteten Werte gegen die zu erwartenden kumulierten Häufigkeiten einer Vergleichsverteilung ab – in der Regel einer Normalverteilung (möglich sind aber auch andere) ● Je stärker sich die Verteilung der Stichprobenwerte und die Vergleichsverteilung ähneln, desto stärker stimmen die empirischen mit den erwarteten kumulierten Häufigkeiten überein, erkennbar am diagonalen Verlauf des Diagramms ● Bei einer perfekten Übereinstimmung von tatsächlicher und theoretischer Verteilung (in der Praxis nicht zu erwarten) liegen sämtliche Punkte auf der eingezeichneten Diagonalen
- 23. Vertiefungsrichtung Marktforschung • Sommersemester 2006 • Christian Reinboth Grafik: Trendbereinigte P-P-Diagramme ● Zusätzlich zum P-P-Diagramm kann auch ein trendbereinigtes P-P-Diagramm ausgegeben werden, bei dem die beobachteten kumulierten Häufigkeiten nicht mit den erwarteten kumulierten Häufigkeiten, sondern mit den Abweichungen der beobachteten von den erwarteten kumulierten Häufigkeiten dargestellt werden
- 24. Vertiefungsrichtung Marktforschung • Sommersemester 2006 • Christian Reinboth Grafik: Q-Q-Diagramme ● Q-Q-Diagramme dienen wie P-P-Diagramme dem visuellen Vergleich einer vorliegenden Verteilung mit einer Referenzverteilung – beispielsweise zur Überprüfung der Voraussetzung einer Normalverteilung ● Im Gegensatz zum P-P-Diagramm werden im Q-Q-Diagramm nicht beobachtete und erwartete kumulierte Häufigkeiten gegenübergestellt, sondern die direkt beobachteten und erwarteten Werte ● Wie im P-P-Diagramm kennzeichnen auch im Q-Q-Diagramm Abweichungen der Punkte vom Verlauf der diagonalen Abweichungen der beobachteten von den erwarteten Werten – ein Indiz dafür, dass die beobachteten Merkmalswerte der Referenzverteilung nicht genügen
- 25. Vertiefungsrichtung Marktforschung • Sommersemester 2006 • Christian Reinboth Grafik: Trendbereinigte Q-Q-Diagramme ● Zusätzlich zum Q-Q-Diagramm kann wie auch beim P-P-Diagramm ein trendbereinigtes Q-Q-Diagramm ausgegeben werden, bei dem die beobachteten Werte nicht mit den erwarteten Werten, sondern mit den Abweichungen der beobachteten von den erwarteten Werten dargestellt werden
- 26. Vertiefungsrichtung Marktforschung • Sommersemester 2006 • Christian Reinboth Grafische Darstellung multivariater Daten Darstellungsformen Bivariate Darstellung Mehr als zwei Variablen 2-D-Streudiagramm Profildiagramme Andrew's Fourier Chernoff-Gesichter 3-D-Streudiagramm Streudiagramm-Matrix
- 27. Vertiefungsrichtung Marktforschung • Sommersemester 2006 • Christian Reinboth Grafik: Streudiagramme ● Streudiagramme stellen die gemeinsame Verteilung der Werte zweier Variablen (bzw. dreier Variablen in einem 3-D-Streudiagramm) dar, indem die entsprechenden Werte beider Variablen gegeneinander abgetragen werden ● Die Lage und Verteilung der Wertepaare ermöglicht Rückschlüsse auf mögliche Zusammenhänge ● Beispiel: Treten in der Tendenz große Werte der einen Variablen gepaart mit großen Werten der anderen Variablen auf, so kann ein positiver Zusammenhang vermutet werden (beispielsweise bei Werbeausgaben und Verkaufszahlen) ● Ein gefundener Zusammenhang kann nicht in eine bestimmte Richtung interpretiert werden, d.h. aus der Grafik ist nicht abzulesen, ob Variable A Variable B beeinflusst oder umgekehrt, bzw. ob ein Scheinzusammenhang besteht
- 28. Vertiefungsrichtung Marktforschung • Sommersemester 2006 • Christian Reinboth Grafik: Streudiagramm-Matrix ● Liegt ein multivariater Fall vor, d.h. sollen für mehrere Variablenpaare jeweils gemeinsame Verteilungen dargestellt werden, ist statt einer Reihe bivariater Streudiagramme ein gemeinsames Streudiagramm in Form einer Matrix sinnvoll ● Eine Streudiagramm-Matrix erlaubt den schnellen Überblick über die Vielzahl aller denkbaren Paarverteilungen und gestattet das rasche Auffinden symmetrischer oder anderweitig auffälliger Einzel-Streudiagramme ● Jedes Streudiagramm taucht zweimal in der Matrix auf (einmal oberhalb und einmal unterhalb der Hauptdiagonalen), wobei die jeweiligen Achsen der Diagramme miteinander vertauscht sind (Gehalt <> Anfangsgehalt; Anfangsgehalt <> Gehalt)
- 29. Vertiefungsrichtung Marktforschung • Sommersemester 2006 • Christian Reinboth Ausreißeranalyse: Einführung ● Bei einem Ausreißer handelt es sich um einen gemessenen oder erhobenen Wert,der nicht den Erwartungen entspricht bzw. nicht zu den restlichen Werten der Verteilung passt ● Es existiert keine klare Definition darüber, wann ein Wert als Ausreißer bezeichnet werden kann- beim Box-Plot z.b. werden alle Werte außerhalb des dreifachen IQR-Bereichs um den Median als Ausreißer klassifiziert ● Es gibt drei mögliche Ursachen für das Auftreten eines Ausreißers: ● Der Ausreißer wurde durch einen verfahrenstechnischen Fehler verursacht, beispielsweise einen Fehler bei der Dateneingabe, beim Codieren der Daten oder einen technischen Ausfall bei der Datenerfassung bzw. -speicherung ● Der Ausreißer kennzeichnet einen außergewöhnlichen Wert, beispielsweise eine einzelne aus dem Rahmen fallende Beobachtung (der einzige befragte Millionär), die sich aber erklären lässt – mitunter können solche Ausreißer auch ein Hinweis darauf sein, dass die Befragung falsch angelegt wurde und daher nicht repräsentativ ist ● Der Ausreißer kennzeichnet einen korrekt erfassten außergewöhnlichen Wert, für den es keinerlei Erklärung gibt ● Generell ist zwischen normalen Ausreißen und multivariaten Ausreißern zu unterscheiden: ● „Normaler“ Ausreißer = außergewöhnlich großer oder kleiner Wert (persönliches Einkommen im Millionenbereich) ● Multivariarer Ausreißer = für sich betrachtet im normalen Bereich liegende Einzelwerte, die in ihrer Kombination quer durch die Variablen einen einzigartigen Fall ergeben (86jährige Frau mit Internetanschluss) ● Die entscheidende Frage der Ausreißeranalyse lautet: Werden die Ausreißer beibehalten oder verworfen?
- 30. Vertiefungsrichtung Marktforschung • Sommersemester 2006 • Christian Reinboth Ausreißeranalyse: Identifikation ● Wie lassen sich Ausreißer erkennen? Unterscheidung in Ausreißer und extreme Werte im Box-Plot Grafische Identifikation von Ausreißern im Streudiagramm Identifikation von Ausreißern über die Extremwerttabelle
- 31. Vertiefungsrichtung Marktforschung • Sommersemester 2006 • Christian Reinboth Ausreißeranalyse: Leverage-Effekt Auswirkung eines Ausreißers auf den Verlauf einer lineare Regressionsgerade Einzelne Ausreißer können die Regressionsgerade zu sich „hinziehen“ und das Ergebnis einer linearen Regressionsanalyse erheblich beeinflussen
- 32. Vertiefungsrichtung Marktforschung • Sommersemester 2006 • Christian Reinboth Ausreißeranalyse: Umgang ● Wie ist nun mit den gefundenen Ausreißern umzugehen? ● Generell gibt es drei Möglichkeiten: ● Ausschluss aus der Analyse ● Eingang in die Analyse ● Kennzeichnung als fehlende Werte ● Verschiedene Überlegungen sind für die Entscheidung von Bedeutung: ● Wie ist das Auftreten der Ausreißer zu erklären? ● Handelt es sich um Eingabefehler und ist es möglich, diese zu bereinigen? ● Was sagen die Werte über Anlage und Durchführung der Erhebung aus? ● Welche Auswirkungen haben die Ausreißer auf die Ergebnisse der Datenanalyse? ● Beeinflussen sie beispielsweise den Verlauf der Regressionsgraden? (Leverage-Effekt) ● Werden die Analyseergebnisse so stark verzerrt, dass die Ausreißer entfernt werden müssen? ● Welcher Datenverlust entsteht, wenn die Ausreißer aus dem Datensatz entfernt werden?
- 33. Vertiefungsrichtung Marktforschung • Sommersemester 2006 • Christian Reinboth Fehlende Daten: Einführung ● Unter fehlenden Daten sind einzelne fehlende Werte zu verstehen ● Typische fehlende Werte bei Personenbefragungen: ● Angaben zum Einkommen ● Angaben zum eigenen Körper ● Angaben zum Sexualverhalten ● Fehlende Werte sind ein Problem, wenn ein Zusammenhang zwischen der Wahrscheinlichkeit des Fehlens und einem anderen Sachverhalt zu vermuten ist, die Verteilung der fehlenden Werte also nicht zufällig ist ● Beispiel: Kommt es bei der Frage nach dem Einkommen tendenziell eher zu Auskunftsverweigerungen bei Personen mit niedrigem Einkommen, so wird dies das erhobene Durchschnittseinkommen verzerren ● Bei der Untersuchung fehlender Daten ist daher vor allem zu klären: ● Fehlen so viele Werte, dass eine sinnvolle Auswertung des Datensatzes unmöglich ist? ● Sind die fehlenden Werte zufällig im Datensatz gestreut oder lässt sich ein Muster identifizieren? ● Generell bieten sich drei Möglichkeiten des Umgangs mit fehlenden Daten an: ● Es werden ausschließlich die vollständigen Fälle zur weiteren Auswertung zugelassen ● Einzelne Fälle oder einzelne Variablen werden von der weiteren Auswertung ausgeschlossen ● Die fehlenden Werte werden induktiv oder statistisch ersetzt
- 34. Vertiefungsrichtung Marktforschung • Sommersemester 2006 • Christian Reinboth Fehlende Daten: Ursachen ● Das Fehlen von Daten kann auf vier Ursachen zurückgeführt werden: ● Dateneingabefehler (z.B. Buchstaben in einem Zahlenfeld) ● Codierungs- und Übertragungsfehler während Eingabe oder Speicherung ● Ungenaue Datenfelder bei der Erhebung (z.B. „Studienrichtung“ bei einer Befragung von Nicht-Akademikern) ● Aktionen des Befragten, beispielsweise Vergessen der Angaben, widersinnige Angaben (höchster Schulabschluss ist die Mittlere Reife, trotzdem wurde eine Abiturnote eingetragen), Nichtauskunftsfähigkeit oder bewusste Entscheidung eine bestimmte Frage nicht zu beantworten (Einkommen, Körper, Sexualverhalten...) ● Fehlende Werte sind bei der Arbeit mit empirischen Daten keine Ausnahme, sondern die Regel ● Die Wahrscheinlichkeit für das Auftreten fehlender Werte steigt im Allgemeinen mit der Größe des Datensatzes ● Bei der Analyse langer Zeitreihen, z.B. der Auswertung der Niederschlagsmengen der letzten 200 Jahre, werden aufgrund von Katastrophen, Krieg oder anderen Gründen immer wieder einzelne Werte nicht erfasst worden sein ● Gerade in der sozialwissenschaftlichen Forschung und bei der Marktforschung im Zuge der Befragung von hunderten oder tausenden Personen kommt es aufgrund verschiedenster Ursachen häufig zu Einzelausfällen Mit fehlenden Daten ist bei jeder marktforscherischen Untersuchung zu rechnen! Das Problem der fehlenden Daten sollte vom Marktforscher nicht einfach ignoriert werden!
- 35. Vertiefungsrichtung Marktforschung • Sommersemester 2006 • Christian Reinboth Fehlende Daten: Zufälligkeitsgrade ● Man unterscheidet in drei Zufälligkeitsgrade bezüglich des Auftretens fehlender Daten: MCAR, MAR und NRM ● Der Zufälligkeitsgrad entscheidet, ob fehlende Werte ausgeschlossen oder ersetzt werden können ● MCAR = missing completely at random ● Fehlende Werte treten vollkommen zufällig auf ● Die Wahrscheinlichkeit des Fehlen eines Wertes steht nicht in Zusammenhang mit anderen Größen ● Es ist kein Zusammenhang zwischen dem Auftreten von fehlenden Werten der Variable Y und der Variable Y selbst (niedrige Einkommen werden tendenziell nicht angegeben) oder eine Korrelation mit einer anderen Variable X (Frauen sind tendenziell weniger bereit, Auskünfte über ihr Körpergewicht zu machen) feststellbar ● MAR = missing at random ● Das Auftreten von fehlenden Werten steht (teilweise) in Zusammenhang mit einer anderen erhobenen Variablen ● Es ist kein Zusammenhang zwischen dem Auftreten von fehlenden Werten der Variable Y und der Variable Y selbst feststellbar, aber eine (schwache) Korrelation des Auftretens von fehlenden Y-Werten mit einer anderen Variable X ● NRM = nonrandom missing ● Das Auftreten von fehlenden Werten folgt klaren Gesetzmäßigkeiten, Zufälligkeit ist auszuschließen ● Es kann entweder ein Zusammenhang zwischen dem Auftreten von fehlenden Werten der Variable Y und der Variable Y selbst oder mit einer anderen Variable X oder auch beides vorliegen, d.h. das Auftreten eines fehlenden Wertes kann vollständig durch eine andere Variable oder die Variable selbst erklärt werden
- 36. Vertiefungsrichtung Marktforschung • Sommersemester 2006 • Christian Reinboth Fehlende Daten: Umgang ● Welche der drei Methoden angewandt werden kann, hängt wesentlich vom Zufälligkeitsgrad ab ● CCA = complete case approach ● Es werden ausschließlich vollständige Fälle für die weitere Analyse verwendet ● Alle Fälle mit auch nur einem fehlenden Wert werden aus dem Datensatz entfernt ● Die Methode kann nur bei zufällig fehlenden Daten (MCAR) angewendet werden ● Günstig ist sie bei einer großen Stichprobe, da die gelöschten Fälle hier unkritisch sind ● Ausschluss von Fällen oder Variablen ● Ziel ist die Verringerung des Gesamtanteils fehlender Werte ● Abwägen zwischen dem Datenverlust und der Reduktion der Probleme durch fehlende Werte ● Günstigste Methode für nicht zufällig auftretende fehlende Werte (MAR, NRM) ● Der Ausschluss von Fällen kann fallweise oder paarweise erfolgen ● Ersetzen fehlender Werte ● Grundidee: metrische Daten (ausschließlich!) lassen sich ersetzen, wenn Regelmäßigkeiten erkennbar sind ● Möglich ist der Ersatz über verschiedene induktive (nichtmathematische) und statistische (mathematische) Verfahren ● Die Gefahr besteht darin, dass man den Datensatz für vollständig hält bzw. durch die Ersetzungen verzerrt
- 37. Vertiefungsrichtung Marktforschung • Sommersemester 2006 • Christian Reinboth Fehlende Daten: Ausschlussverfahren ● Fallweiser Ausschluss: ● Fehlt ein einzelner Wert, wird der komplette Fall von der weiteren Analyse ausgeschlossen ● Vorteil: bestimmte Arten von Asymmetrien werden vermieden, da keine Teilfälle in die Analyse eingehen ● Nachteil: relevantes Datenmaterial geht verloren, der Stichprobenumfang sinkt mit jedem Ausschluss ● Paarweiser Ausschluss: ● Fehlen einzelne Werte, wird mit den restlichen Werten des Falles weitergearbeitet ● Vorteil: alle Fälle bleiben erhalten, der Stichprobenumfang verändert sich nicht ● Nachteil: bei multivariaten Analysen bilden u.U. unterschiedlich große Datensätze die Berechnungsgrundlage ● Um Fälle zu vermeiden, bei denen auf unterschiedlich große Datensätze zurückgegriffen und gleichzeitig verglichen wird, ist der fallweise Ausschluss das weitaus häufiger verwendete Ausschlussverfahren
- 38. Vertiefungsrichtung Marktforschung • Sommersemester 2006 • Christian Reinboth Fehlende Daten: Ersatzwertverfahren ● Induktive Verfahren: ● Die fehlenden Werte werden auf der Basis von Informationen ersetzt, die über die Stichprobe vorliegen ● Nachbeobachtungen: zusätzliche Beobachtungen / Befragungen werden angestellt (Repräsentativität?) ● Externe Konstanten: konstanter Wert aus externer Quelle oder früherer Studie wird ersatzweise verwendet ● Statistische Verfahren: ● Metrische fehlende Werte können aus der Stichprobe geschätzt werden (Voraussetzung ist MCAR) ● Mittelwertersatz: ein fehlender Wert einer Variable wird durch den Mittelwert dieser Variablen ersetzt ● Formen des Mittelwertersatzes: Mittel / Median der Nachbarpunkte, Zeitreihen-Mittelwert & lineare Interpolation ● Vorteil: die Verfahren sind leicht anzuwenden, benötigt werden lediglich die entsprechenden Mittelwerte ● Nachteil: die Varianz, die Verteilung der Daten und eventuelle Korrelationen werden verzerrt ● Linearer Trend: ein fehlender Wert einer Variablen wird durch den linearen Trendwert für diese Variable ersetzt ● Voraussetzung: für die gültigen Werte lässt sich ein sinnvoller linearer Trend ermitteln ● Fehlende Werte können dann durch die Werte der Trendgraden an der betreffenden Stelle ersetzt werden ● Nachteil: der lineare Trend in den Variablen wird verstärkt, die Varianz der Verteilung verringert sich
- 39. Vertiefungsrichtung Marktforschung • Sommersemester 2006 • Christian Reinboth Normalverteilungsprüfung: Einführung ● Die Gauß- oder Normalverteilung ist die wichtigste kontinuierliche Wahrscheinlichkeitsverteilung ● Die zugehörige Dichtefunktion ist als Gaußsche Glockenkurve bekannt ● Eigenschaften: ● Dichtefunktion ist glockenförmig und symmetrisch ● Erwartungswert, Median und Modus sind gleich ● Zufallsvariable hat eine unendliche Spannweite ● Viele statistische Verfahren setzen die Normalverteilung der Daten in der Grundgesamtheit voraus ● Es ist daher häufig zu prüfen, ob von einer solchen Verteilung ausgegangen werden kann (auch näherungsweise) f x= 1 2 e −1 2 x− 2 Erwartungswert Median Modus
- 40. Vertiefungsrichtung Marktforschung • Sommersemester 2006 • Christian Reinboth Normalverteilungsprüfung: Dichtefunktion
- 41. Vertiefungsrichtung Marktforschung • Sommersemester 2006 • Christian Reinboth Normalverteilungsprüfung: Histogramm ● Grafische Analyse mit Histogramm und überlagerter Normalverteilungskurve ● Die Balken des Histogramms spiegeln die Breite der Wertebereiche wieder – da zudem für leere Wertebereiche ein Freiraum ausgegeben wird, kommt im Histogramm die gesamte empirische Verteilung der Variablen zum Ausdruck ● Dies ermöglicht den direkten Vergleich mit einer eingezeichneten theoretischen Verteilung, wie beispielsweise der Normalverteilung ● Der Grad der Abweichung einer Normalverteilung lässt sich auch anhand verschiedener Maßzahlen wie Exzeß (Kurtosis) und Schiefe bestimmen
- 42. Vertiefungsrichtung Marktforschung • Sommersemester 2006 • Christian Reinboth Normalverteilungsprüfung: Q-Q ● Grafische Analyse mit Q-Q-Diagramm und trendbereinigtem Q-Q-Diagramm
- 43. Vertiefungsrichtung Marktforschung • Sommersemester 2006 • Christian Reinboth Normalverteilungsprüfung: K-S-A ● Die Prüfung auf Vorliegen einer Normalverteilung kann auch mit einem Anpassungstests erfolgen ● In SPSS lässt sich dazu beispielsweise der Kolmogorov-Smirnov-Anpassungstest nutzen ● Der Test arbeitet mit der kumulierten empirischen und der kumulierten erwarteten Referenzverteilung ● Die maximale Differenz zwischen beiden Verteilungen wird zur Berechnung der Prüfgröße Z nach Kolmogorov-Smirnov verwendet, mit der dann aus einer Tabelle der für einen Stichprobenumfang n kritische Wert für die maximale Differenz bei einem gegebenen Signifikanzniveau abgelesen werden kann ● Nullhypothese H0 des SPSS-Tests: die Werte der untersuchten Variablen sind normalverteilt ● Berechnet wird die Wahrscheinlichkeit, mit der das Zurückweisen dieser Hypothese falsch ist (Signifikanzwert) ● Je größer diese Wahrscheinlichkeit ausfällt, desto eher ist von einer Normalverteilung der Werte auszugehen ● Im nebenstehenden Beispiel eines Kolmogorov-Smirnov-Tests fällt der Signifikanzwert mit 0,00 so niedrig aus, dass die Annahme der Normalverteilung zurückzuweisen ist ● Bei der Interpretation ist zu beachten, dass es sich um einen Test auf perfekte Normalverteilung handelt ● Anzuraten ist daher die Kombination mit einem der grafischen Prüfverfahren
- 44. Vertiefungsrichtung Marktforschung • Sommersemester 2006 • Christian Reinboth Homoskedastizitätsprüfung: Levene-Test ● Viele statistische Verfahren setzen voraus, dass die Varianzen innerhalb verschiedener Fallgruppen gleich sind (beispielsweise Signifikanztests und Mittelwertvergleiche) ● Gleichheit der Varianzen = Homoskedastizität ● Ungleichheit der Varianzen = Hetroskedastizität ● Mit dem Signifikanztest nach Levene wird die Nullhypothese H0 überprüft, dass die Varianzen in der Grundgesamtheit in allen Gruppen homogen (gleich) sind ● Der Test arbeitet mit dem F-Wert als statistischem Prüfmaß mit bekannter Verteilung ● Es wird getestet, mit welcher Wahrscheinlichkeit die beobachteten Abweichungen in den Varianzen auftreten können, wenn in der Grundgesamtheit absolute Varianzgleichheit herrscht ● Diese Wahrscheinlichkeit wird als Testergebnis ausgewiesen ● Eine geringe Wahrscheinlichkeit weist auf eine Varianzungleichheit hin
- 45. Vertiefungsrichtung Marktforschung • Sommersemester 2006 • Christian Reinboth Grafische Homoskedastizitätsprüfung ● Eine grafische Prüfung auf Homoskedastizität kann mit Streudiagrammen oder Boxplots durchgeführt werden ● Hierbei ist auf die unterschiedlichen Streuungen und die Höhe des Medians zu achten
- 46. Vertiefungsrichtung Marktforschung • Sommersemester 2006 • Christian Reinboth Linearitätsprüfung ● Die Prüfung auf Linearität kann sowohl grafisch als auch statistisch erfolgen ● Grafische Prüfung: Auswertung von Streudiagrammen oder Scatterplots ● Statistische Prüfung: Analyse der Residuen oder Regressionsanalyse
- 47. Vertiefungsrichtung Marktforschung • Sommersemester 2006 • Christian Reinboth Arbeit mit Dummy-Variablen ● Für viele Analyseverfahren wird ein metrisches Skalenniveau vorausgesetzt (z.B. Multiple Regression) ● Sollen nominalskalierte Daten in ein solches Verfahren einfließen, müssen Dummy-Variablen gebildet werden ● Dummy-Variablen sind binäre Variablen, die nur die Werte 0 und 1 annehmen können ● Eine dichotome Variable lässt sich durch Transformation in eine Dummy-Variable überführen ● 0 = Ausprägung liegt nicht vor ● 1 = Ausprägung liegt vor ● Beispiel: Untersuchung der Einflüsse von Verpackungseigenschaften auf das Kaufverhalten ● Dummy-Variable q1 nimmt für rote Verpackungen den Wert 1, für nicht-rote Verpackungen den Wert 0 an ● Analog dazu lässt sich auch eine Dummy-Variable q2 für die Farbe Gelb und q3 für die Farbe Grün definieren ● Existieren nur diese drei Verpackungsfarben kann auf q3 aber verzichtet werden, da: ● Wenn q1 = 0 und q2 = 0 muss q3 = 1 gelten ● Drei Farben lassen sich daher über nur zwei Dummy-Variablen beschreiben ● Generelle Regel: Eine nominale Variable mit n Ausprägungen lässt sich in n-1 Dummy-Variablen abbilden
- 48. Vertiefungsrichtung Marktforschung • Sommersemester 2006 • Christian Reinboth Gibt es noch Fragen?