1. Oracle Database Structrue
System Global Area ( SGA )
Database Buffer Cache
Buffer Pools
Default
8K
Keep Recycle
Non Default
Buffer Pools
2K
4K 32K
16K
Redo
Log
Buffer
Shared Pool
Library Cache
Shared SQL Area
( SQL 쿼리/실행 계획 )
Data Dictionary Cache
Result Cache
Reserved Pool
Large Pool
DBWR
(DB Writer)
LGWR
(Log Writer)
CKPT
( Chekpoint
Process )
SMON PMON ARCH
(Archive
Processor )
Data/Temp/Undo Files
Control Files
Server
Parameter
File
RECO
Redo Log
Files
Archived
Redo Log
Files
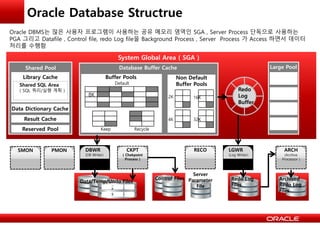
Oracle DBMS는 많은 사용자 프로그램이 사용하는 공유 메모리 영역인 SGA , Server Process 단독으로 사용하는
PGA 그리고 Datafile , Control file, redo Log file을 Background Process , Server Process 가 Access 하면서 데이터
처리를 수행함
2. Oracle Connection & Server Process
Listener
Server
Process
User
Process
User
Process
User
Process
Server
Process
Server
Process
Program Global Area
( PGA )
SQL Work Area
Sort Area
Hash Area
Private SQL Area
…………..
Program Global
Area ( PGA )
SQL Work Area
Sort Area
Hash Area
Private SQL Area
Program Global
Area ( PGA )
SQL Work Area
Sort Area
Hash Area
Private SQL Area
Data/Temp/Undo Files System Global Area ( SGA )
Shared Pool Buffer Cache …...
…………..
Cursor Cursor Cursor Cursor
3. 오라클 아키텍처 구성 요소
우리 몸을 건강하게 유지하는 3대 필수 영양소는
단백질 , 지방 , 탄수화물
오라클 RDBMS 이해를 위한 3대 필수 사항은
프로세스 , 메모리 , 데이타베이스 파일
4. 오라클 아키텍처 구성 요소 설명
프로세스
메모리
데이타베이스 파일
• 사용자 프로세스와 Oracle 프로세스로 구분하며 Oracle 프로세스는 다시
Server Process 와 Background Process로 분류
• Server Process 와 Background Process 의 결합으로 대부분의 Database
Work을 수행
• 오라클 DB를 구성하는 주요 파일로서 주로 사용자 데이터가 저장되는
Datafile 과 DML 과 같은 데이터의 변경사항을 실시간 기록하는 Redo Log
File , 오라클 Structure 주요 변경사항을 기록하는 Control File로 구성
• 많은 Server Process들이 동시에 사용하는 공유 메모리 구조인 SGA 와
Server Process 개별로 할당되는 PGA 영역으로 구분됨
5. 0. DBMS 기반 이해
1. Oracle 데이터 저장구조
2. Oracle 메모리 구조
3. Oracle Database File 구조
4. Oracle Process
5. Oracle 성능 관리 방법론
6. Oracle Enterprise Manager 12c 소개
7. Oracle RDBMS 12c 소개
목차
7. DBMS의 정의
즉 , 데이터를 효율적으로 저장, 갱신, 삭제, 읽기(검색) 등을 할 수 있게 관리하는 소프트웨어가 바로 DBMS
DBMS란 DataBase Management System의 약자로, 데이터베이스를 구성하고, 이를 효율적
으로 응용하기 위해 구성된 소프트웨어를 지칭함
데이터와 응용 프로그램의 중간에서 응용 프로그램이 요구하는 대로 데이터를 정의하고, 읽
고, 쓰고, 갱신하는 등의 데이터를 조작하고 관리하는 프로그램의 집합체가 DBMS임
8. 최적 저장 구조를 위한 고려 사항
데이터를 임의의 공간에 보관 데이터를 약속된 공간에 정확히 보관
• 데이터를 검색 할 시 시간이 더 걸림
• 데이터를 저장 할 시 빠르게 완료됨
• 데이터를 검색 할 시 빠르게 완료됨
• 데이터를 저장 할 시 시간이 더 걸림
데이터의 저장 방식과 검색은 매우 밀접한 관계에 있음. 다양한 데이터 저장 방식을 활용하여 상황에 맞
게 검색 속도를 향상 시킬 필요가 있음
9. 인덱싱을 통한 검색과 Full Scan을 통한 검색
기말고사에 나올 페이지를 표기하기 위해 목차를 참고하여 해당 페이지를 표기하는 것이 빠른가 ? 책 페이
지를 Scan 하면서 표기하는 것이 나은가 ?
목차를 이용한 페이지 표기 페이지 Scan을 통한 표기
명확한 목차 항목의 여부 , 표기해야 할 페이지 수 , 각 표기 페이지 들의 인접성등의 차이에 따라 어떠한
방법이 최적이 될지 결정됨
인덱스를 통한 테이블 Access 테이블 Full Scan
11. Database Block의 정의
DB Block
DB 데이터 검색과 저장의 가장 기본 단위 ( 2k, 4K,8K,16K,32K,64K )
모든 DB I/O 는 DB Block 단위로 수행
보통 Block 당 평균 수십 개의 레코드가 들어갈 수 있는 크기로 구성
단 하나의 레코드만 읽기 위할지라도 최소한 1 Block을 Access 해야 함.
백만개의 Record 를 가지고 컬럼 크기와 값도 서로 동일한 두개의 테이블이 있다. 검색 속도는 서로 동일한가?
12. 클러스터링 팩터
Block Block Block Block Block
Block Block Block Block Block
CASE 1
CASE 2
사용자가 자주 검색하는 비슷한 값들이 얼마나 서로 모여 있느냐에 따라서 액세스 하는 Block
건수가 달라짐. 즉 I/O 횟수가 차이가 나게 됨.
클러스터링 팩터
Select * from Tab where Color = ‘ ’
2 Block Access
4 Block Access
Table
Table
13. 데이터 저장구조 최적화의 이슈 - 1
……..
Block Block Block Block
Block Block Block Block Block
…….
빨간색 영역 초록새 영역 파란색영역
……..
사용자가 입력하는 데이터의 순서는 사용자가 조회하고자 하는 데이터의 순서대로 입력되지 않음
빠른 데이터 입력 속도, 상대적
으로 나쁜 클러스터링 팩터
느린 데이터 입력 속도, 상대적
으로 좋은 클러스터링 팩터
상호간에 분명한 장단점이 존재함. 어떻게 최적화 시킬 것인가?
사용자가 입력하는 데이터를 주어진
블록의 여유공간에 순차적으로 위치
사용자가 입력하는 데이터를 그 값
에 따라 지정된 블록 영역에만 입력
14. Block Block Block Block Block
A
J
C
K
A
O D
C
B
S
B
E
B
C
A
TABLE
데이터 저장구조 최적화의 이슈 - 2
•특정 조건의 검색 최적화를 위해 데이터를 저장하였지만 해당 조건이 아닌 다른 조건으로 검색할 경
우에는 오히려 성능저하가 발생할 수 있음.
•데이터를 바라보는 View는 단일 조건일 수 만은 없으며 다양한 조건 검색을 염두에 두고 데이터 저
장 구조가 설계 되어야 함..
해당 Block은 컬러값으로 조회 시 최대 성능을 내기 위해 최적화 된 구조임.
조회 조건이 컬러가 아닌 , 문자(A,B,C등) 또는 모양 ( 세모,네모, 별,하트) 등
의 다른 조건일 때는 오히려 수행 속도가 저하됨.
컬러값 (빨강,
초록,파랑등)
으로 조회
문자값 (A,B,C
등) 으로 조회
모양값 (세모,
네모,별,하트)
으로 조회
15. Index를 통한 테이블 Access의 클러스터링 팩터
030508
030508030508
030508
030508
030512
AAA
KKKKKK
BBB
DDD
CCC
100
200200
100
300
250
030508
030508
030512
030508030508
030508
NNN
AAA
BBB
KKKKKK
RRR
100
200
100
300300
250
030508
030508030508
030508
030508
030512
AAA
KKKKKK
BBB
DDD
CCC
100
200200
100
300
250
030508
030508
030512
030508030508
030508
NNN
AAA
BBB
KKKKKK
RRR
100
200
100
300300
250
AAA
AAA
……
DDD
……
KKK
PPP
PPP
PPP
KKK
KKK
3 Row,
3 Block030507
030507
030512
030507
030507
AAA
BBB
KKK
HHH
CCC
100
200
100
300
250
INDEX2TABLE
7 Row,
2 Block
INDEX1
030506
030507
030507
030507
030507
030507
030506
030507
030508
030507
030508
030507
030508
030507
030507
030510
AAA
CCC
BBB
AAA
DDD
100
200
100
300
250
인덱스 로우의 순서와 테이블에 저장되어 있는 데이터 로우의 위치가 얼마나 비슷한 순서로 저장 되어 있는가?
클러스터링 팩터가 좋다 클러스터링 팩터가 나쁘다.
Col 1 Col 2 Col 3 Col 1 Col 2 Col 3Col 1 Index Col 2 Index
SELECT * FROM TABLE WHERE COL1 =‘030507’; SELECT * FROM TABLE WHERE COL2 =‘KKK’
동일한 테이블이더라도 검색조건에 따라 클러스터링 팩터가 달라짐.
16. Hard Disk 의 데이터 Access 원리
Hard Disk 는 Spindle과 Head의 기계적인 움직임을 통해 데이터에 액세스함.
이러한 기계적 움직임은 Hard Disk Access 속도의 많은 부분을 차지하고 있음.
데이터의 Access 량 보다 주어진 데이터를 Access하기 위한 기계적 움직임이
얼마나 많았는지가 상대적으로 Hard Disk 의 수행 속도를 더 좌우함.
따라서 자주 Access 해야 되는 Block 을 이동해야하는 Random I/O 의 경우
Hard Disk의 수행 속도가 느려 질 수 있음.
해당 데이터를 Access 하기 위해 Disk 는 어떤 움직임을 해야 하는가?
17. I/O Access 유형
• 보조기억장치에 저장된 파일로부터 정해진 순서대로 데이터를
순차적으로 검색함. 순차 액세스에서는 데이터들이 차례차례로
읽혀짐. 스캔 방식으로 동작함
Sequential Access ( 순차 Scan)
• 어떤 파일 내에 있는 특정한 레코드를 찾을 때 다른 레코드를
순차적으로 읽지 않고 원하는 레코드만을 직접 액세스. 데이터
를 빨리 검색할 수 있는 액세스 방식
• 검색될 레코드를 명시하기 위해서는 임으로 액세스 하려는 레
코드들은 그들과 관련된 key를 가져야 함
Random Access ( 임의 Access )
• 데이터를 읽어 들이거나 기록하기 위해 디스크 드라이브의 판독
/기록 헤드의 위치를 표면 위의 특정 트랙으로 이동시키는데 소
요되는 시간.
디스크 Access Time ( Seek Time)
Table Full Scan
Index 를 경유한 Table
Random Acess
1 블록이 I/O 단위
Multi 블록을 I/O 단위로 사용 가능,
DB_FILE_MULTIBLOCK_READ_COUNT로
설정
18. 테이블 Access I/O 유형
1
2
3
4
5
6
7
8
9
10
테이블 Block
Access 순서
인덱스
(컬럼 = ‘컬러’)
테이블
테이블
1
10
………….
인덱스 스캔을 통해 알게된 Rowid 값을 가지
고 Table을 Access함
( Row id는 테이블의 위치를 알수 있는 고유값 )
인덱스를 통해 테이블을 Access할 경우 테이
블 Block Access 순서가 Random 이 되는
Random I/O 발생
대부분의 OLTP 성 Application은 Random
I/O Access 유형
테이블은 인덱스를 경우하지 않을 경우
Segment의 처음부터 끝까지 순차적으로 Full
Scan 함
데이터를 읽는 량은 Random I/O 보다 많을
수 있으나 대용량의 데이터를 읽을 경우는
Random I/O 보다 훨씬 효율적
인덱스를 경유한 Table Random Access
Table Full Scan
19. Random I/O 증가량에 따른 성능 변화
1만건의 Record를 Access 하기 위해서 Random I/O 시 1,000 Block 이 필요하고 Full Scan 시 십만
Block 필요할 경우 어떤 Access 가 더 빠른가 ?
백만건의 Record를 Access 하기 위해서 Random I/O 시 십만 Block 이 필요하고 Full Scan 시 천만
Block 필요할 경우 어떤 Access 가 더 빠른가 ?
Random I/O , Full Scan 모두 Disk I/O 로 가정
• 특정 TABLE의 컬럼값 분포도가 균일하게 10% 일 경우 , 가령 컬럼값 A,B,C,D,E,F,G,H,I,J 열 종류가 모두
균일하게 건수가 같은 경우
• 1억건이 넘는 대용량 테이블에 해당 컬럼으로 단독 인덱스를 생성할 것인가 ?
• 만일 동일 테이블에 해당 컬럼값 분포도가 균일하게 1%라면 , 가령 컬럼값이 100종류이면 모두 균일
하게 건수가 같다면 해당 컬럼으로 단독 인덱스를 생성할 것인가?
20. Table Full Scan 과 Random I/O 비교
수행시간
Access 해야되는 Record 수 ( Block 수 아님)
Full Scan은 1건을 Access하거나 백만건을 Access 하
거나 모든 Block을 Access 해야 하므로 Access Record
건수에 따른 수행시간 변화가 거의 없음.
인덱스를 경유한 Random I/O는 Access 해야 하는 Record
가 늘어나면 Block Access 건수도 같이 증가
Random I/O Block Access 건수가 일정 수치이상 증가하면
수행 시간이 급격하게 느려지게 됨.
1
2-22-1 2
Full Scan
Random Access
H/W 성능 및 DB 기능에 따라 2-1, 또는
2-2 의 성능 변화가 가능
21. Disk Storage의 Stripping
Physical
Hard Disk
Group
LUN
Group
또는 LVM
Storage 에 RAID 0 Stripping을 한 경우 I/O 가 균일하게 모든 Disk Drive에 동시에 수행되어 빠른 시
간안에 I/O 처리
23. Oracle Database Structure
Tablespace
Extent Extent Extent
Extent Extent Extent
Extent
Block Block Block
Block
`
Segment
Extent Extent Extent
Extent Extent Extent
Segment
……… ………
Logical Database Structure
Physical Database Structure
Datafile Datafile Datafile
os
오라클 DB의 I/O를 위한 기본 단위임. DB내에 가장 작은
Building Block 이며 DB 생성 시에 그 크기가 정해짐
( 4K,8K,16K,32K 등 )
몇 개의 연속된 Block으로 이뤄져 있으며 , Segment 의
공간을 증가 시킬 때 할당 되는 기본 Space 단위
여러 개의 Extent로 구성되어 있으며 테이블 또는 인덱스
와 같은 Object
여러 Segment 들이 모이는 데이터 저장 공간으로서 여러 개의
Datafile이 모여서 만들어진 논리적인 데이터 저장공간.
24. Database Block 개요
Database I/O 의 최소 기본 단위
하나의 Record 에 접근하더라도 반드시 1 Block을 읽어야 함
9i 이전에는 최초 DB 생성시에 Block 크기가 결정되나 9i 이후 부터는
Tablespace 별로 서로 다른 DB Block 크기 할당 가능
DB_BLOCK_SIZE 파라미터 값이 Default Database Block 크기임
Database Block
Row 1
Row 2
Row 3
OLTP 용 DB에서는 상대적으로 작은 Block ( 8K ) , DW/Batch에
서는 상대적으로 큰 Block Size 할당 ( 16K,32K 등)
최근에는 DB의 기능 향상 및 서버/Storage 성능 향상으로 인하여 Block
Size를 8K 이상 증대시킬지라도 큰 성능향상 기대는 어려움
25. 표준 및 비 표준 블록 크기 설정 방안
블록 크기 설정 방안 내용
표준 블록 크기 설정 DB_BLOCK_SIZE 파라미터를 사용하여 데이터베이스 생성 시 설정되며 변경 불가.
Default Buffer Cache는 DB_BLOCK_SIZE에 설정된 Block size를 기준
비 표준 블록 크기 설정 9i 이후 테이블스페이스 별로 별도의 블럭크기를 설정 가능
SYSTEM 및 TEMPORARY 테이블스페이스는 표준 블록으로만 지정 가능
테이블 스페이스 용도별로 OLTP, DSS/배치등의 사용되는 Object의 검색 성능을 증대
시키기 위해 도입됨. => 그러나 잘 사용되지 않음.
nK Block으로 Tablespace가 생성될 경우 DB_nK_CACHE_SIZE 파라미터를 이용하여
Non Default Buffer Cache 구성함.
CREATE TABLESPACE TBS_1 DATAFILE ‘tbs_1.dbf’ SIZE 10M BLOCKSIZE 16K;
비표준 블록 크기 테이블스페이스 생성
26. 데이터베이스 블록 구성
헤더
사용 가능 영역
데이터 영역Row 3
Row 2
Row 1
트랜젝션이 블록 행을 변경할 때 사용하는 트랜잭션 슬롯, 데이터 블록주
소,테이블 디렉토리, 행 디렉토리가 존재
데이터는 블록의 초기의 끝부분에
서 상향식으로 블록에 삽입
블록의 사용 가능 영역이 해당 블록의 중간에 있으므로 필요한 경우 헤더
및 데이터 공간이 성장할 수 있음. 초기에는 연속적이나 데이터의 Delete
나 Update등으로 인하여 단편화 됨. 필요한 경우 블록의 사용 가능 영역
을 병합 수행
실제 데이터가 입력되는 영역이며 데이터는 상향식으로 블록에 입력
데이터베이스 블록은 헤더, 사용가능영역, 데이터 영역으로 구성되어 있음.
27. 블록 공간 활용 파라미터
Row 3
Row 2
Row 1
인덱스나 데이터 블록에서 생성되는 트랙잰션 슬롯의 초기 개수와 최대
개수를 지정. 트랜잭션 슬롯은 한 시점에 블록을 변경하는 트랜잭션에 대
한 정보를 저장하는 데 사용
해당 블록의 행 Update 시를 대비해 미리 예약해둔 공간의 백분율
테이블의 각 데이터 블록을 유지하기 위해 사용한 최소 공간의 백분율.
블록은 사용된 공간이 PCTUSED 보다 작으면 다시 사용 가능 영역 목록
에 올려짐
INITRANS &
MAXTRANS
PCTFREE
PCTUSED
블록 공간 파라미터를 활용하는 최적의 전략은 하나의 Block 안에 되도록 많은 Row를 저장하되, 하나의 Row
가 2 Block 이상에 저장되는 것을 막는 것임.
Row 4
DB I/O의 기본은 Block 임. 하나의 Row를 읽기 위해 2개 이상의 Block을 액세스 하지 않도록 파라미터 조정
28. 데이터 블록 관리
블록 관리 유형 블록 관리 방안
수동 관리
• 테이블,인덱스 등의 세그먼트의 Storage Parameter 인 PCTUSED, PCTFREE,
FREELISTS 등을 수동으로 설정하여 관리
• Object 유형 및 Transaction 유형 별로 사용자가 설정하여 관리 어려움
자동 세그먼트 공간 관리
• Locally Manage 테이블스페이스 레벨에서 자동 세그먼트 공간 관리 설정
• PCTUSED,PCTFREE,FREELISTS, FREELIST GROUPS 등의 파라미터를 자동으로
관리하므로 사용이 용이함
• 수동관리보다 공간 활용률이 더욱 향상.
• 다양한 동시액세스에 대한 런타임 조정기능으로 동시처리 기능 향상
CREATE TABLESPACE data02 DATAFILE ‘/u01/oradata/data02.dbf’ SIZE 100M
EXTENT MANAGEMENT LOCAL UNIFORM SIZE 5M
SEGMENT SPACE MANAGEMENT AUTO;
자동 세그먼트 공간 관리 명령어
29. 블록 공간 활용 메커니즘 - 수동
PCTFREE=20 , PCTUSED=40 인 데이터 세그먼트에 대해 블록 내의 공간 관리법
1. 해당 블록의 사용가능영역이 20% 이하가 될때까지 행이 행당 블록으로 삽입. 행이 블록의 사용가능한 데이터 공
간중 80%( 100 – PCTFREE) 이상을 차지하면 해당 블록에 더 이상 삽입 될 수 없음
2. 나머지 20%는 행 크기가 증가할 때 사용할 수 있음. 예를 들어 원래 Null 이었던 열에 값을 지정하여 Update할
경우 블록 활용이 80%를 초과하게 됨.
3. 행이 블록에서 삭제되거나 갱신 결과 행 크기가 감소되면 블록 활용이 80% 미만으로 내려가지만 블록은 블록
활용이 PCTUSED 40% 미만으로 내려가야 다시 삽입 작업에 사용
4. 데이터 저장이 PCTUSED 미만일 때 다시 해당 블록에 사용가능하며 다시 주기가 1단계 부터 반복
• 한 행이 1 Block이상에 저장되지
않도록 초점이 맞춰짐 메커니즘.
• 빈번하게 Update게 발생하는 테
이블일 경우 PCTFREE의 값을 상
대적으로 크게 설정
30. Extent의 필요성
Segment
Block Block
Block Block
Block Block
Block Block
• Extent 가 없다면 신규 데이터를 입력할때 Block 생성을 DB에 자주 요구해야 함
• 만일 수천~수만개의 Record 가 입력된다면 Block 생성 요구는 급증하게 되어
DB 성능에 큰 부담
Segment
Block Block
Block Block
Block Block
Block Block
Block
Block
Block
Block
Block
Block
Block
Block
Block
Block
Block
Block
Block
Block
Block
Block
Block
Block
Block
Block
Block
Block
Block
Block
A 세그먼트 초기 Block 정렬 B 세그먼트 초기
Block 정렬
C 세그먼트 초기
Block 정렬
D 세그먼트 초기
Block 정렬
• Extent가 없다면 세그먼트가 생성시에 만들어진 초기 Block 정렬들이 데이터가 입력
됨에 따라 여러 세그먼트의 Block 들이 서로 인접하게 됨에 따라 클러스터링 팩터가
매우 나빠지게 됨
Block
반복적인 저장공간 요청 시의 부하 증가
효율적인 블록 저장 정렬이 어려워짐으로 인한 클러스터링 팩터의 저하
추가 데이터 입력
서로 다른 세그먼트의 Block들이 인접됨
Extent가 없이 Block 단위로
Segment의 공간이 할당된다면?
31. Extent 할당
Table Segment
Extent
Block Block
Extent
Block Block
Extent
신규 데이터 입력에 따라 신규 블록 할당이 필요할 경우
먼저 여러 Block들이 한꺼번에 모여있는 Extent 를 할당함
많은 신규 데이터가 입력되더라도 Block 할당요청을 빈번히
할 필요가 없으며 , 다른 세그먼트가 비슷한 영역에 신규로
Block을 할당할 확률도 적어지므로 특정 Segment Access
시 속도도 향상됨.
그러나 아직 사용되지 않는 Block을 미리 공간 할당을 하므
로 약간의 저장공간을 더 사용하게 됨.
Extent는 Segment 내에서 공간을 할당하는 단위. Extent 의 Size등은 Segment 의 Storage Option 으로 부여하거나
Tablespace 에서 자동 부여
32. Segment의 유형
Table 이나 Index 등의 Object 가 Space 할당된 것을 Segment 라 함.
테이블 파티션 테이블
클러스터 인덱스
• 데이터베이스 내에 데이터를 저장하는 가장 일반적인 수단임.
• 테이블 세그먼트 내의 데이터는 특정 순서로 저장되지 않으며 사용자는 테이
블에 있는 블록내의 행 위치에 대해 거의 제어할 수 없음
• 테이블 세그먼트는 하나의 테이블 스페이스에 저장되어야 함.
테이블
• 여러 세그먼트가 분할(파티션)되어 있는 구조이나 하나의 테이블로서 사용 가
능함
• 대용량 데이터의 관리를 위해서 반드시 필요한 구조임
• Range , Hash, List , Composite 와 같은 다양한 유형으로 파티션됨
• 각각의 세그먼트는 서로 다른 테이블스페이스에 할당 가능함.
파티션 테이블
• 테이블의 특정 컬럼값으로 해당 Row를 찾기 위한 색인 세그먼트
• B-Tree와 Bitmap 인덱스로 구성 ( 여기서는 B-Tree 만 논함 )
• 파티션 인덱스가 아닌 경우는 하나의 테이블스페이스에 저장되어야 함
인덱스
Segment 유형
33. Segment의 유형
Segment 유형
IOT 파티션 인덱스
Undo 세그먼트 임시 세그먼트
• Primary Key 인덱스와 테이블이 동일한 세그먼트 상에 존재함.
• PK 인덱스를 Access하는 동시에 테이블 Access가 가능하여 Random I/O 성능
향상
• 그러나 PK 컬럼외에 다른 컬럼으로 조회 시 오히려 성능 저하 이슈 발생
IOT(Index Organized Table)
• 파티션 테이블 또는 일반 테이블에 대한 인덱스를 파티션 할 수 있음
• 주로 파티션 테이블 사용시 인덱스도 파티션 함.
파티션 인덱스
• 데이터 값을 변경할 때 이전의 값을 저장하는 세그먼트
• 변경 취소 시에 해당 값은 Undo 세그먼트로 부터 참조 되어 취소
Undo 세그먼트
• Sort , Group by , Hash join 시 Temporary 테이블스페이스에 임시 세그먼트를
생성하여 작업 수행
임시 세그먼트
34. Block 11 Block 12Block 10
Block 14 Block 15Block 13
10번 Block
11번 Block
13번 Block
Free List
• Pctused의 값 이하 블록에 대한 집합
• Free List는 Default 1의 값을 가지고 있음
• 시스템적 특성에 따라 가변적으로 적용
Segment Header
Segment 데이터 저장영역
Free List
Block 10
Free space
153 102
378
27 765
234
124
26 433
• 임의의 위치에 로우 저장
• 요구한 순서대로 저장
• 보유한 데이터의 값과 무관
빈 블록 사용 가능
빈 블록
Table 세그먼트의 데이터 입력 관리
Free List에서 비어있는 , 사용가능한 Block 리스트를 조회하고 해당 block에 데이터 입력
1 세그먼트에 데이터 입력 요구
2
비어있는 10번 Block에 데이터 입력
35. B-Tree Index
Reverse key Index
Order_no Rowid
1011121
2611121
3411121
3711121
4911121
5011121
…………
9211121
AAAHW7AAB AAAMUi
AAAHW7AAB AAACDf
AAAHW7AAB AAAMpj
AAAHW7AAB AAAMUi
AAAHW7AAB AAACqE
AAAHW7AAB AAAMUi
………….. ………
AAAHW7AAB AAARSq
AAB
AAA
AAF
AAA
ABB
AAH
…..
AAC
Reverse key Index
Order_no Rowid
1011121
2611121
3411121
3711121
4911121
5011121
…………
9211121
AAAHW7AAB AAAMUi
AAAHW7AAB AAACDf
AAAHW7AAB AAAMpj
AAAHW7AAB AAAMUi
AAAHW7AAB AAACqE
AAAHW7AAB AAAMUi
………….. ………
AAAHW7AAB AAARSq
AAB
AAA
AAF
AAA
ABB
AAH
…..
AAC
Order_no 컬럼 인덱스
컬럼값과 해당 컬럼값의 테이블 Row가 위치해 있는 Rowid 값으로 구성되어 있음.
인덱스에서 해당 컬럼값을 조사한 뒤 Rowid를 이용하여 Table 에 Access 함.
ROWID를 통해 테이블 Access
36. B-Tree 인덱스 세그먼트의 생성
Temp Segment
Index
Root block
Branch block
Leaf
block
①
② ③
④
데이터 정렬 -> 인덱스 세그먼트의 리프 블록에 기록(① ) ->
리프 블록이 PCTFREE에 도달 -> 새로운 리프 블록과 브랜치 블록 생성(② )->
리프 블록이 추가될 때마다 브랜치 블록에 로우를 추가하며 작업 계속 ->
브랜치 블록이 PCTFREE에 도달 -> 새로운 브랜치 블록(③ )과 루트 블록 생성 (④ )
37. 데이터 삭제/갱신 시 인덱스 세그먼트 변경 내역
삭제 flag만 표시하므로 저장 공간 낭비, 범위 스캔 대상 증가
리프 블록의 대부분의 로우가 삭제되었다 하더라도 범위 스캔 시에는 액세스될 수 있음.
모든 ROW가 삭제되면 블록을 INDEX FREELIST에 등록하여 자원관리
삭제 시
로우의 삭제와 삽입이 동시에 진행됨.(삭제는 flag만 표시)
저장 공간의 낭비와 트리 구조의 깊이가 증가
삭제된 ROW가 동일 값으로 다시 입력되면 ROWID가 변경된 상태로 원래 블록에 생성
갱신 시
삭제와 갱신으로 인하여 인덱스 Skew( 치우침) 현상 발생
해결방안은 인덱스의 재생성(rebuild)-재생성이 보다 효과적
데이터의 처리(DML)가 많이 수행되는 테이블은 정기적인 재생성 필요
38. 파티션 테이블
• 대용량의 Table을 Partition이라는 보다 작은 단위로 나눔으로써 데이터 액세스 작업의 성능 향상을
유도하고 데이터 관리를 보다 수월하게 하고자 만들어짐
• 하나의 테이블로서 액세스하지만 여러 개의 Segment로 구성이 가능하며, 각 Segment에는 파티션
KEY 값 또는 범위에 해당하는 Row 들만 저장될 수 있음.
• Range , List , Hash 로 단독 파티션 구성 및 이들을 결합한 Composite 파티션도 가능
39. 파티셔닝의 장점
1999
2000
2001
…
2001
1999
2000
2001
…
• 파티션 별로 독립적인 백업 및 복구
• 시스템 장애 발생시 데이터의 손상정도
최소화
• 불필요한 데이터 액세스 방지
(Partition Pruning)
• I/O 분산에 의한 성능향상
• 독립적인 DML문 수행
(다른 파티션에 영향을 주지 않고
각 트랜잭션 수행 가능)
Partitioning
일반 테이블 파티션 테이블
40. Oracle Advanced Compression Option
• Oracle 의 ACO 를 사용하여 압축을 통한 데이터 저장공간을 절약 ( 2배에서 최대 4배까지 ) , 검색 속도
향상 등의 개선
• 압축된 테이블에 DML 등의 데이터 변경 시에도 수행 속도 저하가 거의 없음.
OLTP 테이블의 압축 수행 프로세스
41. ACO Index Compression
Non Unique Index의 경우 중복되는 키 컬럼 값을 압축 수행하여 인덱스 세그먼트의 사이즈를 대폭 감소
• 중복 컬럼 값을 감소하여 스토리지 공간 절약
• Leaf block에 더 많은 Key값 저장
• Index Range Scan 시 I/O 성능 향상
42. 클러스터링 팩터 향상 전략
Unbalanced
Index
Re-balanced
Index
테이블 재생성 인덱스 재생성
Chained Table Re-organized Table
정렬된 테이블 재생성
Sorting Table
소극적 전략
42
적극적 전략
파티션 테이블 생성 Segment 압축 적용
H/W 가 발달하고 DBMS 기능이 점차 향상됨에 따라 테이블이나 인덱스 재생성과 같은 소극적인 클러스터링 팩
터 향상 전략으로는 큰 성능향상이나 스토리지 절감효과를 기대하기 어려움. 파티션 테이블이나 Segment 압축등
과 같이 보다 적극적인 전략으로 클러스터링 팩터를 향상 시키는데 노력을 기울여야 함.
44. Oracle Memory Structure
Shared Memory Non Shared Memory
( Private)
PGA PGA PGA
Server
Process
Server
Process
Server
Process
Server
Process
Server
Process
Server
Process
……..
……..
Server
Process
Server
Process
Server
Process
PGA PGA PGA
Server
Process
Server
Process
Server
Process
SGA( System Global Area)
• Disk I/O 를 최대한으로 줄일수 있는가?
• 동시에 많은 프로세스에서 최대한 효율적으로 자원할당을 할 것인가?
• 시스템 안정성을 어떻게 유지할 것인가?
매우 많은 서버 프로세스가 동시에 메모리 자원을
공유
각 서버 프로세스가 개별 메모리 할당
( PGA : Program Global Area )
오라클의 메모리 활용 전략
45. Oracle SGA 의 개요
System Global Area ( SGA )
Database Buffer Cache
Buffer Pools
Default
8K
Keep Recycle
Non Default
Buffer Pools
2K
4K 32K
16K
Redo
Log
Buffer
Shared Pool
Library Cache
Shared SQL Area
( SQL 쿼리/실행 계획 )
Data Dictionary Cache
Result Cache
Reserved Pool
Large Pool
Database Buffer Cache : Disk I/O의 영향도를 줄이기 위해 데이터 파일의 데이터 블록을 메모리로 Copy
Shared Pool : 사용자들간에 SQL 및 SQL 실행 계획을 공유하기 위한 메모리 공간
Redo Log Buffer : 데이터 변경사항 ( DML 발생시) 정보를 가지며 Redo log file에 Write 되기 이전에 Memory에 먼저
Write 되는 영역
Large Pool : Parallel Query 메시징 또는 대용량의 메모리 할당이 필요한 경우 사용됨.
Java Pool : Java Object에 대한 메모리 영역
46. Instance 와 Database 에 대한 용어 정의
Instance란?
- Background Process와 SGA 메모리 영역을 일컫는다. 따라서 Instance를 시작하게 되면
SGA영역을 할당하고 Background Process를 구동시키게 된다.
Database란?
- 데이터베이스를 저장하는 물리적 영역이라고 할 수 있다. dbf 파일, control 파일, log 파
일 등 데이터를 저장되어 있는 물리적 공간이라고 생각하면 된다.
… … ……
Background Process
SGA 메모리
… … ……
Background Process
SGA 메모리
… … ……
Background Process
SGA 메모리
Instance Instance Instance
Data/Temp/Undo
Files
Control
Files
Redo
Log
Files
Data/Temp/Undo
Files
Control
Files
Redo
Log
Files
Data/Temp/Undo
Files
Control
Files
Redo
Log
Files
Database Database Database
47. Buffer Cache를 통한 데이터 Access
Database Buffer Cache
Buffer Pools
Default
id=001
Id=002
id=003
Id=004
id=005
Id=006
id=007
Block 1 Block 2 Block 3 Block 4
id=008
Id=009
id=010 id=011 id=012
Id=013
Block 5 Block 6 Block 7 Block 8
Select * from customer where id=‘005’
……
LRU
(Least Recently Used)
Customer
Block 1
메모리 위치
Customer
Block 7
메모리 위치
Customer
Block 2
메모리 위치
Customer
Block 8
메모리 위치
1 Data Dictionary 등의 내부 정보를 통해서 Customer 테이블의
id=‘005’ 데이터가 있는 Block의 Storage 위치 정보를 알아냄
2
해당 Block의 Storage 위치는 알았으나 Buffer Cache에 이미 올라
가 있는 Block 인지 확인하기 위해 LRU 검색
LRU는 특정 Block이 Buffer Cache에 등록되어 있는지, 등록되어
있다면 Buffer Cache내의 위치가 어디인지 정보를 가지고 있음.
3
LRU를 Scan 하였지만 대상 Block 이 없다면 이는 Buffer
Cache에 존재하지 않는 것이므로 1에서 얻어낸 위치정보
로 Disk에 Access
id=005
Id=006
Customer Table
4 디스크의 해당 Block을 Buffer Cache에 올림.
LRU의 맨앞에 해당 Block에 대한 정보를 등록
Customer
Block 3
메모리 위치
Disk Storage
48. Buffer Cache 내 블록 유형 (Free/Dirty/Pinned Buffer)
Database Buffer Cache
Buffer Pools
Default
Free Buffer: 아직 데이터가 할당되지 않은 buffer block. 디스크에서 읽은 신규 데이터를 할당 가능함.
Pinned Buffer: 데이터가 할당된 후 수정되지 않고 사용자 세션에 의해 사용되고 있는 Buffer block.
Dirty Buffer: 데이터가 이미 할당된 이후에 다시 데이터가 수정되었으나 아직 disk 상의 data file에 Write 되지 못한
Buffer block.
Free Block
Dirty Block Val =
4 -> 5
Val =
10
Pinned Block
1
Select * from customer where val = 4
Select * from customer where val = 10
1
2 Update customer set Val = 5
where val = 4 Update 시 속도 향상을 위해서 해당 block을 Disk로 바
로 내리지 않고 buffer cache에 그대로 값 변경 적용
49. Database Buffer Pools 의 유형
Database Buffer Cache
Buffer Pools
Default
8K
Keep Recycle
Non Default
Buffer Pools
2K
4K 32K
16K
Default Buffer Cache : DB_BLOCK_SIZE 에서 정의된 Block Size로 Block이 할당된 Buffer Cache
로서 별도의 Storage Option 이 없으면 Table/Index등의 Object는 Default Buffer Cache에 등록
Keep Buffer Cache : Table/Index 등의 Object를 Keep Buffer에 등록하면 Buffer Cache에서 내려
오지 않고 지속적으로 유지됨. 자주 쓰이는 조회성 데이터의 메모리 Hit Ratio를 높이기 위해 사용
Recycle buffer cache : 메모리에 Object가 올라온 뒤에 해당 Transaction이 종료된 후에는 다시
메모리에서 제거됨. 거의 사용되지 않음.
1
2 3
1
2
3
DW성 , 이력 통계 데이터와 같은
대용량의 데이터를 Access해야 할
경우 큰 Block Size가 상대적으로
유리함.
이를 위해 DB_BLOCK_SIZE 에 기술
된 SIZE와 다른 BLOCK 크기를 가진
테이블 스페이스 생성 가능.
(2K,4K, 16K,32K 등 )
이와 같은 용도로 생성된 테이블스
페이스 상의 Object 에 Access 할
경우 Non Default Buffer pool 을
이용
DB_BLOCK_SIZE = 8K 일 경우
50. Buffer Pool 유형 Buffer Cache 유형 크기 설정 파라미터
Default Buffer pool
Default Buffer Cache DB_CACHE_SIZE
Keep Buffer DB_KEEP_CACHE_SIZE
Recycle Buffer DB_RECYCLE_CACHE_SIZE
Non Default Buffer Pool Non Default Buffer Cache DB_nK_CACHE_SIZE
(n 은 Kbyte block size
2,4,8,16,32 중 하나 )
Database Buffer Pools 의 유형
Keep Buffer에 Object 등록: ALTER TABLE CUSTOMER STORAGE ( BUFFER_POOL KEEP)
Recycle Buffer 에 Object 등록: ALTER TABLE CUSTOMER STORAGE ( BUFFER_POOL RECYCLE)
Default Buffer 활용 :ALTER TABLE CUSTOMER STORAGE ( BUFFER_POOL DEFAULT)
명령어
DB_KEEP_CACHE_SIZE = 48MB
DB_RECYCLE_CACHE_SIZE=24MB
DB_CACHE_SIZE=128M /* Standard DB_BLOCK_SIZE 8K */
DB_4K_CACHE_SIZE=48MB /* Non Standard DB_BLOCK_SIZE 4K */
DB_16K_CACHE_SIZE=192MB /* Non Standard DB_BLOCK_SIZE 16K */
DB_32K_CACHE_SIZE=384MB /* Non Standard DB_BLOCK_SIZE 32K */
총 Buffer Cache 크기
는 824MB
51. Buffer Cache Hit Ratio
시스템이 얼마나 Disk I/O 를 줄이고 Buffer Cache를 잘 활용하
고 있는지를 나타내는 지표
Hit Ratio = (1 – ( Physical reads/Logical Reads ) ) * 100
• Logical Reads : Buffer Cache Block 액세스 수
• Physical Reads : Disk Block 액세스 수
일반적으로 90% 이상의 수치 보장 필요
90% 이하 수치는 나쁜 것인가 ? 90% 이상 수치는 항상 좋은 것인가?
52. Buffer Cache Hit Ratio 통계 함정 – 1
Buffer Cache Hit Ratio 99%이면 전반적인 SQL 수행속도가 양호한 것일까?
십만의 1%는 천, 그러나 십억의 1%는 천만
100,000의 1% 1,000,000,000의 1%
만일 Application 전체적으로 SQL들이 Block을 많이 Access해야 되는 잘 튜닝되어 있는 않은 SQL이라면 ?
수백 , 수천개의 SQL 중 단 1%의 SQL 들의 호출빈도가 전체 SQL 호출 빈도에 대부분을 차지하게 된다면?
SQL
SQL
SQL
SQL
SQL
• 호출 빈도수가 매우 높으면서 Access Block
수는 많은 SQL 들이 Buffer Cache를 지속적
으로 점유하게 되면 Logical Reads 는 크게
증가하게 됨.
• 이들을 제외한 다른 많은 SQL들은 Buffer
Cache 공간을 차지할 기회가 상대적으로 적
어 디스크 Access 를 많이 하게 되나 워낙
Logical Reads 수치가 높아 Buffer Cache Hit
Ratio가 높게 나오는 현상 발생
TOP SQL들
SQL SQL SQL SQL SQL
SQL SQL SQL SQL SQL
다른 수많은 SQL Buffer Cache 공간이 작아
디스크 Access함.
53. Buffer Cache Hit Ratio 통계 함정 -2
Hit Ratio와 같은 통계 정보는 불균일한 데이터 분포가 발생할 경우
정확한 문제 상황을 제대로 제공할 수 못할 가능성이 있음
퍼센트가 아닌 절대 일량 수치 ( 메모리 Access량 , 디스크 Access
량)을 기준으로 성능 평가 필요
Buffer Cache Hit Ratio 외에 Load Profile + Wait
Event 를 결합한 분석 필요
54. SQL 실행계획 영향 요소
SELECT count(*) CNT
FROM je040dt a, jx051dt b, je020dm c WHERE a.doc_serial = b.srl_no AND
a.proc_status > '00‘ AND b.doc_code = c.doc_code
AND b.rec_dt BETWEEN TO_DATE (? || '000000', 'YYYYMMDDHH24MISS')
AND TO_DATE (? || '235959', 'YYYYMMDDHH24MISS')
AND a.owner_bmen_no = ? AND INSTT_CODE_SE=?
Je040dt 테이블에
proc_status 인덱스가
있는가?
Je040dt 테이블의 크기
는 얼마인가?
Je040dt 테이블에
owner_bmen_no인덱
스가 있는가?
Jx051dt 테이블에
doc_code 인덱스가 있
는가?
Jx051dt 테이블에
rec_dt 인덱스가 있는가?
JE040DT 테이블에
INSTT_CODE_SE 인덱
스가 있는가?
JE020DM 테이블의 크
기는 얼마인가
JX051DT 테이블의 크
기는 얼마인가
............
............
어느 테이블을 선행
집합으로 드라이빙
할 것인가 ?
Nested Loop Join?
또는 Hash Join ?
Full Table Scan ?
Index Range Scan ?
………
Optimizer 가 최적 실행 계획 판단
55. Optimizer 판단의 영향요소
SELECT …
FROM TAB
WHERE ...
SQL 형태
힌트 사용
SELECT …
/*+ FULL */
FROM ...
DBMS, 버전
DB2
=, LIKE, …
A = ‘상수’,
A = :변수…
사용컬럼,
연산자 형태 통계 정보
옵티마이져 모드
RULE
All_rows
First_rows
OPTIMIZER
인덱스,
테이블 구조
시스템 및
네트워크
상태
분산 DB
56. 실행계획 생성을 위한 고려 요소
Cost 비교
Cost 비교 Cost 비교
Cost 비교 Cost 비교
Cost 비교
Cost 비교
Cost 비교
Cost 비교 Cost 비교Cost 비교
Rows Row Source Operation
------- ---------------------------------------------------
1 SORT AGGREGATE
13 TABLE ACCESS BY INDEX ROWID JE040DT
4165876 NESTED
7875 NESTED LOOPS
12686 TABLE ACCESS BY INDEX ROWID JX051DT
12686 INDEX RANGE SCAN S1_JX051DT (object id 53093)
7875 TABLE ACCESS BY INDEX ROWID JE020DM
12686 INDEX UNIQUE SCAN PK_JE020DM (object id 53058)
4158000 INDEX RANGE SCAN S10_JE040DT (object id 53084)
수많은 선택의 요소 최종 결정된 실행 계획
많은 CPU 및 I/O 일량 필요
최종 결정된 실행 계획은 수많은 선택의 요소를 상호
Cost 비교하여 가장 최적의 결과 값으로 선택된 것임.
이를 위해 많은 CPU 및 I/O 일량이 필요함.
특히 OLTP와 같은 초당 수십~수백개의 SQL이 동시
에 들어올 경우 반드시 SQL 및 실행계획의 공유가
필요함.
57. Optimizer SQL 실행계획 수행 절차
SQL
Parser
Query
Transformer
Estimator
Plan
Generator
Row Source
Generator
Parsed
Query
Transformed
Query
Query +
Estimates
Query
Plan
Schema Objects Statistics
• 데이터 딕셔너리의 통계정보(데이터의 분포도, 테이블 저장구조, 인덱스 구조, 파티션 형태, 비교연
산자 등을 감안하여 각 실행계획의 비용을 계산
• 사용자가 실행한 SQL은 데이터 딕셔너리를 참조하여 파싱을 수행.
• 옵티마이져는 파싱 결과를 이용해 논리적으로 적용 가능한 실행계획 형태를 선택하고,힌트를 감안
하여 일차적으로 잠정적인 실행계획들을 생성
• 실행계획들의 산출된 비용을 비교하여 가장 최소의 비용을 가진 실행계획을 선택(최저가 입찰 방식
이므로 항상 최적의 결정이라고만 할 수는 없음)
Syntax Check &
Semantics Analyze
1
2
3
58. Hard Parsing 과 Soft Parsing
Hard Parsing Soft Parsing
SQL
Parser Query
Transformer
Estimator
Plan
Generator
Schema
Objects
Statistics
생성된 실행계획을
Library Cache에 보관
SQL 및 실행계획이 Library Cache에 존재하지 않아 SQL의 실행
계획을 처음부터 Parsing, Transforming , Estimating , Plan
Generation 등의 복잡한 단계를 거쳐서 만들어 지는 Parsing
SQL
Parser
Object 에 대한 사
용자 접근 권한
기존에 Library Cache에 있는
SQL 실행계획 사용
SQL 및 실행계획이 Library Cache에 존재하므로 해당
Object에 대한 사용자 접근 권한정도만 확인한 뒤에 Library
Cache에 있는 SQL 실행 계획을 그대로 사용하는 Parsing
Hard Parsing 이 높아 질수록 CPU 부하 , 특히 Library Cache의 Latch 관련 자원 사용률이 매우 높아져서 시
스템 장애를 일으킬 정도의 부하를 유발할 수도 있음.
SQL의 첫번째 사용시에는 Hard Parsing이 필요하나 이후에는 반드시 Soft Parsing이 될 수 있어야 함.
SQL Bind 변수의 필수 사용등으로 거의 대부분의 SQL은 Soft Parsing으로 유도 할 것
59. Shared Pool 구조
Shared Pool
Library Cache
Shared SQL Area
( SQL 쿼리/실행 계획 )
Data Dictionary Cache
Result Cache
Reserved Pool
SQL 또는 PL/SQL 코드를 모두 보관하는 장소
사용된 SQL 및 실행계획이 파싱 되어 보관됨.
Select * from customer where id=‘005’
Hard Parsing Soft Parsing
해당 SQL이 Library
Cache에 존재하는가 ?
No Yes
테이블/인덱스등의 Ojbect 정의, 사용자명,
Role , 권한등의 정보를 보관하는 장소
주로 사용자가 해당 Object에 접근 가능 권한이
있는지 확인하는데 사용
사용자 SQL의 결과 값을 지속적으로 보관
동일한 SQL이 요청될 경우 Buffer 나 Disk I/O
Access 작업을 수행하지 않고 Result Cache에
있는 값을 그대로 반환
60. SQL Bind 변수 사용의 필요성
Select * from Customer where cust_id = ‘100000’
Select * from Customer where cust_id = ‘200001’
Select * from Customer where cust_id = ‘200002’
• Optimizer는 SQL 의 문자 하나만 차이가 생겨도 서로
다른 SQL 로 인식
• 왼쪽의 3개 SQL 은 모두 서로 다른 SQL로 인식되며 첫
번째 호출된 SQL에서 생성된 실행계획은 다른 SQL과
서로 공유할 수 없으므로 모두 Hard Parsing 수행
• 위와 같은 Literal SQL 형식으로 Application 이 작성되
고 많은 동시 접속 사용자에 의해 사용된다면 Hard
Parsing으로 인한 시스템 부하가 급증 가능성 존재
Select * from Customer where cust_id = :1
Select * from Customer where cust_id = :1
Select * from Customer where cust_id = :1
Bind 변수
• SQL에 Bind 변수를 사용하면 Optimizer에서 실행 계획
생성이 완료된 후에 변수값을 후에 호출하여 SQL을 수
행하겠다는 것임.
• 따라서 왼쪽 3개 SQL 은 모두 같은 SQL 로 인식하고 첫
번째 호출된 SQL만 Hard Parsing 되고 이후에 호출되는
모든 SQL은 모두 Soft Parsing 됨.
• OLTP에서 사용되는 거의 모든 SQL들은 반드시 Bind 변
수 형식으로 작성되어야 함.
• JDBC 를 사용하는 경우 PreparedStatement 객체로 구
현 가능
Literal SQL
Bind 변수 SQL
61. SQL 공유 강화를 위한 파라미터 설정
이미 Bind Variable을 사용하지 않은 수많은 SQL들을 Bind 변수를
사용하도록 SQL을 수정하는 것은 많은 노력과 테스트가 필요함.
비슷한 SQL들을 Library Cache에 공유하기 위해서 Optimizer가 동
일한 SQL로 인지할 수 있는 기능 필요
Select * from Customer where cust_id = ‘100000’
Select * from Customer where cust_id = ‘200001’
Select * from Customer where cust_id = ‘200001’
ALTER SYSTEM SET CURSOR_SHARING = ‘FORCE’;
• CURSOR_SHARING 모드를 FORCE로 설정
함으로 왼쪽의 3개 SQL은 Bind 변수를 사
용한 것과 유사하게 SQL을 공유하게 되고
동일한 실행계획을 가짐.
• Oracle 9iR2 이전 버전에서는 버그가 발생
할 수 있으므로 이후부터 적용 필요
62. Redo Log Buffer의 역할
Redo Log Buffer
모든 데이터의 변경정보를 메모리에 임시 보관
DML 처리 시 Redo Log File I/O 성능 향상을 위해서 Redo Log Buffer
가 사용되며 Redo Log Buffer에 있는 데이터는 바로 Redo Log File 에
기록되지 않고 특정한 조건을 만족할 경우에만 일시에 Write 됨
Redo Log File I/O 성능 향상을 위해 사용
LOG_BUFFER 파라미터를 사
용하여 Buffer 크기를 조절
수십MB 정도로 설정
• 사용자가 Commit 할 경우
• Redo log buffer 가 1/3 정도 Full 된 경우
• Buffer cache의 free 공간이 없어서 변경 데이터를 Flush 해야 할 경우
Log Writer 가 redo log buffer 도 함께 redo log 에 Write 함.
63. Redo Log Buffer 의 활용
Database Buffer Cache
Buffer Cache
1
Data에 변경사항 DML 발생
( Insert , Update , Delete )
Redo Log Buffer
2
변경 데이터
LGWR
(Log Writer)
Redo Log Files
DML 등으로 데이터의 변경이
발생할 경우 Buffer cache의 해
당 Block내 값을 변경한 뒤에 바
로 Redo Log Buffer 에 변경전/
후 값을 전달
Redo Log Buffer 에 변경 전/
후 값 전달
3
LGWR 을 통해 Redo Log File
에 Write
UPDATE CUSTOMER SET SIDO = ‘서울 특별시’ WHERE SIDO = ‘서울’
변경전/후 값 : 서울->서울 특별시 사용자가 Commit 할 경우
Redo log buffer 가 1/3 정도 Full 된 경우
Buffer cache의 free 공간이 없어서 변경 데
이터를 Flush 해야 할 경우 Log Writer 가
redo log buffer 도 함께 redo log 에 Write
함.
64. • Commit을 1건당 수행하지 않고 모든 데이터를
Insert 한 뒤에 마지막에 Commit
• PL/SQL 사용시 Collection을 사용하여 데이터 Insert
INSERT INTO ORDER_TMP
SELECT * FROM ORDER WHERE ORDER_DATE < ‘2013-01-01’;
Commit;
• 만일 입력 대상 테이블이 DB 장애 발생 시에 백업/
복구할 필요가 없다면 Nologging Option 적용
INSERT INTO ORDER_TMP NOLOGGING
SELECT * FROM ORDER WHERE ORDER_DATE < ‘2013-01-01’;
Commit;
• 데이터공간 절약에 제약 받지 않는다면 Append
Option 적용
INSERT /*+ APPEND */ INTO ORDER_TMP X NOLOGGING
SELECT * FROM ORDER WHERE ORDER_DATE < ‘2013-01-01’;
Commit;
• PARALLEL DML 을 이용하여 PQ가 병렬로 수행할
수 있도록 함.
• 이 경우 H/W CPU 성능 등을 감안하여 PQ Degree
설정
ALTER SESSION ENABLE PARALLEL DML;
INSERT /*+ APPEND PARALLEL(X 16) */ INTO ORDER_TMP X
NOLOGGING
SELECT /*+ PARARALLEL(A 16) */ * FROM ORDER A WHERE
ORDER_DATE < ‘2013-01-01’;
Commit;
DML (특히 Insert) 성능향상을 위한 다양한 방안
수천만건의 데이터를 DML 수행할 경우 PL/SQL의 For Loop을 사용하여 한건 DML 후 Commit을 반복적으로 사용
하는 것은 수행 시간이 크게 저하됨. 아래와 같은 방식으로 개선 필요
해당 테이블에 Index 가 없다고 가정할 경우
65. PGA ( Program Global Area )
Server
Process
Program Global Area
( PGA )
SQL Work Area
Sort Area
Hash Area
Private SQL Area
각 Server Process가 공유하는 SGA와는 달리 PGA는 각 Server Process 개별적으로 할당되
는 메모리임.
Cursor & Data Fetch
SQL 바인드 변수
SQL Runtime Memory Structure
SQL의 Sort by , Group by 와 같이 정렬이 필요할 경우 디스크 I/O 를 감소
해쉬 조인시 디스크 I/O를 감소
거의 모든 정렬 및 Hashing 작업이 메모리에서 수행될 수 있도록 PGA 사이징의
적정 조절 필요
정렬이나 Hashing 시 디스크 I/O를 줄이기 위해 PGA를 사용
66. PGA를 활용한 SQL 정렬 메커니즘
Server
Process
Program Global Area
( PGA )
SQL Work Area
SELECT * FROM CUSTOMER ORDER BY CUSTOMER_NAME DESC
데이터 정렬
PGA
PGA 메모리에서 정렬
가능한 데이터 량만
큼만 1차로 정렬
Program Global Area
( PGA )
SQL Work Area
데이터 정렬
PGA
추가 정렬을 위해
Temporary Tablespace 1차
정렬 데이터를 내리고 PGA
메모리를 비움
추가 데이터를 다시
PGA에서 2차 정렬
Temporary Tablespace
최종 정렬을 위해 Temp
Tablespace에 정렬 데이
터 내림 Temp Tablespace에서
최종 정렬
정렬 대상 데이터
1
2
3
4
5
정렬해야 할 대상이 작으면 PGA
메모리 내에서 정렬이 가능하므로
정렬 속도가 빠름
정렬해야 할 대상이 크고 PGA의
크기가 작으면 Temp Tablespace
를 활용해야 하므로 정렬 속도가
느려짐
67. PGA 크기 조절을 위한 파라미터
DB Version 파라미터 명 파라미터 설명
9i 이전 SORT_AREA_SIZE Sort 및 Group by 를 위해 PGA에서 최대 할당 가능한 메모리
SORT_AREA_RETAINED_SIZE PGA에서 정렬작업이 완료된 후에도 Server Process가 계속 가지고
있어야 되는 기본 정렬 메모리 공간
HASH_AREA_SIZE Hash Join을 위해 PGA에서 최대 할당 가능한 메모리
HASH_AREA_RETAINED_SIZE PGA에서 Hash Join 작업이 완료된 후에도 Server Process가 계속
가지고 있어야 되는 기본 Hash 메모리 공간
9i 이후 WORKAREA_SIZE_POLICY AUTO로 설정할 경우 오라클이 PGA_AGGREGATE_TARGET에 기술
된 메모리 내에서 최적화된 정렬 및 Hashing등을 위한 공간을 동
적으로 자동 할당. ( 가장 바람직한 방식 )
MANUAL로 설정할 경우 9i 이전과 마찬가지로 정렬과 Hashing을
위한 별도 파라미터 지정값으로 메모리 할당 ( SORT_AREA_SIZE 등
을 활용 )
PGA_AGGREGATE_TARGET WORKAREA_SIZE_POLICY가 AUTO로 지정될 경우 자동으로 확장
가능한 최대 PGA 영역
9i 이전에는 PGA크기 조절을 위한 세부 파라미터들을 모두 사용자가 정해야 하므로 메모리 최적화에 어려움이 있었으
나 9i 부터는 자동으로 PGA를 동적 할당하기 위한 파라미터가 적용됨
68. PGA 메모리 조절 방식
Manual 로 PGA 메모리를 조절하는 모드에서는 , 더 이상 사용되지 않는 PGA 메모리가 자동으로 반환되지 않음.
일정 수준의 PGA 메모리를 Holding 하고 있다가 Session 이 Log off 되는 순간에 비로서 모두 반환됨.
자동으로 PGA를 관리하는 모드에서는 사용되지 않는 모든 메모리를 OS 에 반환함.
PGA_AGGREGATE_TARGET을 5 GB 로 설정하더라도 오라클이 PGA에 즉시 5G를 할당하지 않으며 해당 세션이
메모리를 사용하는 정도에 따라 최대 5G까지 증가하고 사용되지 않을 경우 자동으로 반환됨.
오라클의 자동 PGA 메모리 관리 방식을 적용하는 것이 가장 바람직함
ALTER SYSTEM SET WORKAREA_SIZE_POLICY= AUTO
69. 대용량 데이터 처리 시 수동 PGA 설정 및 유의점
대용량 데이터를 정렬,Group by, Hashing 할 경우 수행 속도를 향상 시키기 위해 Session 레벨에서 PGA 관련
메모리 파라미터를 수동으로 설정
이 경우 Parallel Query 사용에 극도로 유의하여야 함.
ALTER SESSION SET WORKAREA_SIZE_POLICY=MANUAL;
ALTER SESSION SET SORT_AREA_SIZE=404857600; /*+ 정렬용 400M */
ALTER SESSION SET SORT_AREA_RETAINED_SIZE=404857600; /*+ 정렬이 완료된 후에도 400M 그대로 유지 */
ALTER SESSION SET HASH_AREA_SIZE=404857600; /*+ HASHING용 400M */
SELECT /*+ NO_PARALLEL(A) */ SVC_CNTR_NO, PRDC_CD, EFCT_STRT_DT,EFCT_END_DT, PRDC_HIST_SRL_NO
FROM MIG_SVC_CNTR_PRDC_HIST A , PRDC_INFO B WHERE A.PRDC_CD = B.PRDC_CD
GROUP BY SVC_CNTR_NO, PRDC_CD, EFCT_STRT_DT, EFCT_END_DT, PRDC_HIST_SRL_NO
HAVING COUNT( * ) > 1 ;
ALTER SESSION SET WORKAREA_SIZE_POLICY=AUTO;
Session 레벨에서 PGA 메모리 파라미터를 수동 조정
다시 PGA 메모리 자동할당으로 설정
SQL 수행을 위해 해당 Session 에 할당된 PGA 메모리는 정렬용 400M + Hashing용 400M 로 총 800M 임
만일 Parallel SQL 을 /*+ Parallel ( A 8 ) Parallel (B 8) */ 과 같이 사용할 경우 각 Parallel Server 개별에 800M 까지 할당
되어 800 *8 = 6.4G 까지 메모리가 사용될 수 있음. 이 경우 시스템 가용 메모리 상황에 따라서 심각한 장애를 유발할 수
도 있으므로 Parallel Query 사용시에는 반드시 유의해야 함.
만일 해당 SQL을 Parallel Query로 수행한다면 ?
70. Insert Transaction 처리 메커니즘
사용자가 Listener 통해 오라클 서버에 접속한 뒤 Server Process 생성
해당 유저가 Insert SQL 을 대상 Object에 수행할 권한이 있는지 Shared Pool의 Data Dictionary Cache에서 확인. 만일
Shared Pool에 없다면 Disk의 Data dictionary를 읽어서 확인
권한이 있다면 , 해당 Insert SQL 이 Shared Pool에 Library cache에 있는지 확인. 만일 SQL이 Library Cache에 없다면
Disk 로 부터 실행계획을 만들기 위한 모든 정보를 가져와서 새롭게 실행계획 수립 ( Hard Parsing)
Insert에 필요한 데이터가 현재 Buffer Cache에 있는지 확인. 만일 없다면 Disk 상의 테이블 데이터를 읽음.
다른 서버 프로세스가 동일한 데이터를 동시에 변경하는 것을 막기 위해서 row level rock을 해당 레코드에 적용
변경분 데이터를 redo log buffer에 기록
Buffer cache에 신규 데이터를 insert 함.
Insert Transaction을 종료하기 위해 사용자가 Transaction을 Commit. Row level rock이 release 됨.
Log writer 가 redo log buffer에 있는 변경 값들을 Online Redo log 에 write함.
서버 프로세스는 사용자에게 Insert Operation이 성공적으로 종료되었음을 통보함 ( Commit Complete )
71. System Global Area ( SGA )
Database Buffer Cache
Redo
Log
Buffer
Shared Pool
Library Cache
Data Dictionary Cache
Server Process
Data dictionary Cache에서 User 권한 체크
Library Cache에서 해당 SQL 및 실행 계획 검색
SQL Parsing
System 테이블 일반 테이블
1차로
Shared
Pool 검색
2차로 디스크의 Data dictionary등
을 검색하여 신규 실행 계획 수립
신규 생성된 실행계획을
Library Cache에 등록
데이터 Insert및 Row Level Lock
Disk에 읽은 데이터를
Buffer Cache에 등록
Insert Transaction 처리 메커니즘
Disk Storage
Buffer Cache 에 해당 데이터가 등록되어 있지
않으면 디스크에서 읽음
Row level Lock 적용
Redo log 파일
변경 데이터를 Redo Log Buffer 에 기록
1
2
4
5
6
7
8
9 Commit 시 Redo Log
파일에 기록하고
Row Level Lock 해제
3
73. Physical Database Structure
Datafile
Table과 Index 등의 모든 Object를 저장하는 파일
Control File
Database Structure 핵심 변경사항에 대한 정보를 가지는 파일
( SCN , Tablespace/Datafile 변경등 )
Redo Log File
테이블 데이터에 대한 변경사항을 기록하는 파일
Physical Database Structure는 Operation System 레벨의 실제 Oracle database file 임.
완벽한 데이터 정합성
74. Control File
물리적 데이터베이스의 현재 상태를 정의한 작은 이진 파일
데이터베이스의 무결성 유지 관리하는 핵심 파일
데이터베이스 시작 시 Mount 단계에서 부터 필요
Control File
그 중요도로 인하여 사용자는 Control
File 정보를 직접 볼 수 없음.
75. Control File 내용
데이터베이스 이름 및 식별자
데이터베이스 생성 시간
테이블 스페이스 이름
데이터 파일 및 온라인 리두 로그 파일의 이름과 위치
현재 온라인 리두 로그 파일의 시퀀스 번호
체크포인트 정보
언두 세그먼트의 시작과 종료
리두 로그 아카이브 정보
백업 정보
SCN (System Change Number) : 가장 최근 Commit 변경에 대해 부여된 고유 수치 값
Control File 내용
데이터베이스 운영에 필요한 기본 Structure 뿐만 아니라 오라클 DB의 다양한 장애에 대비한 백업
과 완벽한 데이터 정합성을 보장하는 복구에 필요한 가장 중요한 정보를 가지고 있음.
76. Control File 다중화
CONTROL_FILES =
$HOME/ORADATA/u01/ctr101.ctl , $HOME/ORADATA/u02/ctr102.ctl , $HOME/ORADATA/u03/ctr103.ctl
Ctr101.ctl Ctr102.ctl Ctr103.ctl
Control File은 반드시 서로 다른 물리적 디스크에 각 복사본을 저장하여 다중화 하여야 함.
77. 온라인 Redo Log File의 필요성
Commit 된 모든 Transaction은 완벽하게 저장되어야 하며 어떠한 상황에서도 완벽하게 복구 되어야 한다
Redo Log File의 필요성
Redo
Log
Buffer
Online Redo Log File Archive Log File
Commit
• 테이블 데이터의 모든 변경사항이 기록됨
• 많은 트랙잭션들이 Commit 시 바로
Datafile에 변경을 기록하게 되면 Write
I/O 가 과다 발생하여 수행 성능 저하되
므로 Online Redo Log 에 일차 기록함.
• Commit 발생할 경우 기록되는 일차 파일
이므로 데이터 복구를 위해 매우 중요함.
반드시 그룹으로 다중화 되어야 함.
• Redo Log File이 다 차게 되면 현 Redo
Log File을 별도의 Archive Log File로 생
성하고 Log switch
• DB 복구 시 매우 중요한 파일이므로 별도
의 Tape 등의 Storage로 백업 수행
• Commit 되지 않은 Transaction
은 수행 성능 향상을 위해
Redo Log File에 바로 Write되
지 않고 Redo Log Buffer 에 먼
저 기록됨
78. Redo Log File 내용
트랜잭션의 시작되었음을 알리는 구분자
트랜잭션 고유명
DML 되고 있는 Object명 ( 테이블 명 )
트랜잭션 Before Image ( 변경 전 데이터)
트랜잭션 After Image ( 변경 후 데이터)
Commit 이 되었음을 알리는 구분자
Redo Log File 내용
79. 온라인 리두 로그 파일 구조
첫 번째 Log Switch 두 번째 Log Switch
세 번째 Log Switch ( 순환되어 첫번째 Log 그룹이 초기화됨)
동일 그룹내의 리두 로그 파
일 멤버들을 물리적으로 분
리된 디스크에 다중화 구성
온라인 리두 로그 파일 그룹
온라인 리두 로그 파일 멤버
• 온라인 리두 로그 파일의 동일한 복사본 모음
• LGWR 프로세스는 그룹에 있는 모든 온라인 리두 로그 파일에 동일한 정보를 동시에 기록
• 데이터베이스의 정상적인 운영을 위해 최소 두 개의 온라인 리두 로그 파일 그룹이 필요
• 그룹에 있는 각 온라인 리두 로그 파일
• 그룹에 있는 각 멤버는 동일한 로그 시퀀스 번호 및 크기를 가짐
• 로그 시퀀스 번호는 오라클이 온라인 리두 로그 파일을 고유하게 식별하기 위함. 로그 시퀀스
번호는 Control File과 데이터파일 헤더에 기록
80. 온라인 리두 로그 파일 작동 방법
Redo
Log
Buffer
리두 로그 그룹 1 리두 로그 그룹 2
리두 로그 파일
Log Switch
DBWR
프로세서
Buffer Cache
Datafile
CKPT
프로세서
Control File
체크 포인트
체크포인트가 정상적으로 완료 되었음을
Control File에 기록
DBWR은 Log Switch 시 이전 로그파일에 기록
되어 있는 Buffer Cache의 Dirty Buffer 를
Datafile에 기록
Update Customer where
address like ‘….%’
사용자가 Commit 할 경우
Redo log buffer 가 1/3 정도 Full 된 경우
Buffer cache의 free 공간이 없어서 변경 데이
터를 Flush 해야 할 경우 Log Writer 가 redo
log buffer 도 함께 redo log 에 Write 함
리두 로그 파일에 기록하는 경우
온라인 리두 로그 파일은 순환 방식으로 사용
온라인 리두 로그 파일이 가득 차면 LGWR을 다음 로그 그룹으로 이동
• 로그 스위치를 호출 하며 체크포인트 작업도 발생
• Control File에 정보를 기록
81. 로그 스위치 및 체크 포인트 수행
로그 스위치 명령어
ALTER SYSTEM SWITCH LOGFILE;
체크 포인트 명령어
ALTER SYSTEM CHECK POINT;
82. Database 기동 단계
No Mount 단계
Open 단계
Mount 단계
• Spfile 또는 Pfile 기술된 정보 인식
• SGA 할당
• Background Process 기동됨
• Alert Log 파일 열어서 기동 프로
세스 기록
• Spfile에 지정된 Control File
• 데이터 파일과 온라인 리두 로그
파일의 이름 및 상태를 알기 위해
Control 파일을 읽음 ( 이때 이들
파일에 대한 존재 여부까지는 확
인하지 않음 )
• Control File에 기술된 온라
인 데이터 파일 및 온라인
리두로그 파일 열기
• 사용자가 데이터베이스에
연결하여 작업 수행 가능
주로 데이터베이스 복구 작업
동안에 Mount 단계가 활용됨
84. 오라클 프로세스의 유형과 역할
Background Process
Server Process
User Process
오라클 인스턴스가 시작될 경우 시작
Database 파일들 및 Instance에 대해 성능 및 안정적 유지관리, 장애 예방 및 복구 ,
데이터 정합성 유지등의 작업을 수행하는 다양한 오라클 내부의 프로세스
오라클 서버와 직접 상호 작용을 하며 사용자가 세션을 설정할 때 시작
User Process와 연계되어 생성된 SQL Call 을 수행하고 결과를 반환
데이터베이스 사용자가 오라클에 연결을 요청할 때 사용자 쪽에 생기는 프로세스
오라클 인스턴스와 직접 상호 작용하지 않으며 Server Process를 통하여 상호작용함.
SQL Plus 와 같은 사용자 인터페이스 툴을 사용하여 User Process 생성
85. 오라클 프로세스들의 수행 개요
User
Process
1 사용자가 DB에 Connection 을 리스너를 통해 요청
SQL-Net , JDBC, ODBC …등의
Connection Protocol
Listener Server
Process
Program Global Area
( PGA )
2 리스너는 연결을 처리할 Server Process를 신규 생성
System Global Area ( SGA )
Shared Pool Buffer Cache …...
DBWR
(DB Writer)
LGWR
(Log Writer)
CKPT
( Chekpoint
Process )
SMON PMON ARCH
(Archive
Processor )
RECO
Data/Temp/Undo Files
Control Files
Redo Log Files
Database
Background Process
Server Process는 데이터 처리를
위해 SGA와 Datafile을 Access
3
SQL Plus
등 사용자 툴
Background Process는 Database 에 대한 다양
한 관리 작업을 수행
0
86. 백그라운드 프로세스의 유형
선택적 백그라운드 프로세스
데이타베이스가 정상 기동 되기 위해서 반드시 필요한 프로세스
DBWn , PMON, CKPT, LGWR, SMON
필수 백그라운드 프로세스
데이터베이스의 다양한 추가 기능 및 RAC 구성등에 따라 구동되는 프로세스
ARCn, CJQ0, Dnn,LCKn,LMDn,LMON,LMS,Pnn,QMNn,RECO
87. DBWn 역할 및 동작
System Global Area ( SGA )
Buffer Cache
Dirty Block
DataFilesDBWR
서버
프로세스
• DBWn 은 데이터베이스 버퍼 캐시의 더티 버퍼를 데이터 파일에 기록함
• 버퍼 캐시에 사용 가능한 버퍼 영역을 다시 확보 가능하게 함.
• 서버 프로세스는 Buffer Cache에서만 데이터를 수정하고 DBWn이
Datafile에 대한 Write를 일괄 수행하므로 전체 DB 성능 향상
• 체크 포인트가 발생하는 경우
• 더티 버퍼가 임계값에 도달한 경우
• 사용 가능한 버퍼가 없는 경우
• 일정 시간 초과가 된 경우
• 테이블 스페이스가 OFFLINE 되거나 READ ONLY 설정 된 순간
• 테이블이 DROP 또는 TRUNCATE 인 경우
• 테이블 스페이스가 Begin Backup 인 경우
DBWn 동작하는 경우
88. LGWR (Log Writer)
Redo Log Buffer
LGWR
(Log Writer)
Redo Log Files
사용자가 Commit 할 경우
Redo log buffer 가 1/3 정도 Full 된 경우
DBWn이 블록 변경사항을 Datafile에 기록하기 전에
3초 마다
DBWn
Log Switch가 발생하여
DBWn 이 데이타파일에
Write 할 것을 요청
CheckPoint
DBWn이 동작하기 전에 먼저 LGWR에
Redo Log File에 기록할 것을 요청함
LGWR은 Redo Log Buffer에 있는 내용을 Redo Log File에 기록하는 역할 수행
DBWn과 다양한 상호작용을 통해 데이터베이스의 정합성 및 안정성을 유지 할 수 있도록 적절한 역할을 분담 수행
89. SMON ( System Monitor )
장애 발생등으로 인스턴스가 갑자기 Down 된 경우 인스턴스 복구 작업을 수행
• 온라인 리두 로그 파일의 변경 사항을 롤포워드
• 사용자 액세스를 위해 데이터베이스 오픈
• 커밋되지 않은 트랜잭션을 롤백
사용 가능한 공간을 병합
임시 세그먼트의 할당을 해제
SGA
Redo
Log
Buffer
Buffer Cache
리두 로그 파일
Datafile
비 정상 Instance
종료 발생
Commit 된 데이터가 리두로그 파일에는 기록되었으나 Datafile에
는 기록되지 못함
SMON롤 포워드
SMON이 리두 로그 파일에 있
는 데이터를 기준으로 Datafile
에 데이터를 롤 포워드 시킴으
로 인스턴스 복구 수행
90. PMON(Process Monitor)
서버 프로세스등이 비 정상 종료 되었을 경우 할당된 서버 자원 및 트랜잭션 Lock을 해제함.
Buffer Cache
서버
프로세스
서버 프로세스가
비정상 종료됨
Table
SGA
PGA
Table Lock 또는 아직 커밋되
지 않은 DML 수행 중
PMON
• 비 정상 종료된 서버 프로세스의 트랜
잭션을 롤백
• 테이블 및 행, 또는 기타 Latch 등의
자원 잠금을 해제
92. DB 성능 및 운영관리를 위한 중요 모니터링 요소
Wait Event
성능 및 운영 관리를 위해 알아야 할 가장 중요한 요소
오라클은 서버프로세스 또는 백그라운드 프로세스가 DB의 CPU , Memory , Database
File, I/O 등의 모든 자원을 액세스하고 이용하는 세부 단계별로 모든 Wait Event ( 대기
이벤트) 를 발생
오라클의 모든 성능 요소 및 자원 사용현황은 Wait Event 의 발생정도에 따라 모니터링
가능함
Load Profile ( 메모리/디스크/Transaction 수 등의 사용 부하)와 결합되어 더욱 세밀한
분석이 가능함.
Alert Log
& Trace File
DB에 장애가 발생할 시 가장 먼저 확인해야 할 파일은 Alert Log 파일임.
오라클은 DB 관리상 중요한 상태 변경사항 및 장애 발생에 관련된 모든 요소를 Alert Log
에서 관리함. (기동/셧다운/백업시작및 종료/Redo log group의 이동/ Datafile의 변경사
항/ 백그라운드 프로세스의 상태 변경, Archive log 파일의 생성,checkpoint 발생 등 ,
ORA-XXX 등 장애 발생 )
Trace File은 상세한 문제 분석이 필요할 경우 오라클이 이에 대한 Trace 등을 수행하여
생성되는 파일
93. DB 내 문제점 진단과 분석을 위한 Wait Event
Database Buffer
Cache
Redo
Log
Buffe
r
Shared Pool
Library Cache
Data Dictionary
Cache
Server
Process
Data/Temp/Undo Files Redo Log Files
Server
Process
Server
Process
Server
Process
Server
Process
Server
Process
Back Ground
Process
Back Ground
Process
Back Ground
Process
Server
Process
Wait
Event
Wait
Event
Wait
Event
Wait
Wait
Event
Wait
Event
Wait
Event
Wait Event Wait Event Wait Event
Wait EventWait Event Wait Event
인체내의 각 기관별로 진단을 위한 다양한 증상 및 이에 대한 해결책을 발전시켜 왔듯이 , 오라클은 DB내의 거
의 모든 세부 프로세스 절차에서 Wait Event를 의무적으로 발생시키는 성능 분석 Framework 을 발전시켜 옴.
94. Wait Event는 오라클의 DB 성능 개선 노력의 산물
오라클 내부에서 처리되는 거의 세부 프로세스들은 각 단
계별로 고유의 Wait Event 를 생성
이는 Oracle이 성능 및 시스템 문제 분석과 진단, 개선을 위
해 얼마나 많은 공을 들이고 있는지를 알 수 있는 반증.
오라클의 Wait Event 종류는 모두 가지가 넘음.
성능 , 문제점 들에 대한 완벽한 진단 및 개
선을 위한 오라클의 철저한 노력의 산물
95. Idle Wait Event & Non Idle Wait Event
Idle Wait Event Non Idle Wait Event
세션이 Inactive 상태에서 Work을 수행 준비하
는 단계에서 발생하는 Wait Event
DB 성능에 전혀 영향을 미치지 않는 Wait
Event
DB내에서 Active Work 처리 과정중에 발생하
는 Wait Event
DB Time에 포함되어 중점적인 성능 모니터링
요소인 Wait Event
96. 주요 Wait Event들
Wait Event를 알기 위해서는 반드시 먼저 오라클의 Process , 메모리 , 데이타베이스 파일들로 구성되는 내부처리
아키텍처를 이해해야 함
모든 Wait Event를 아는 것은 불가능하며 , 주요 Wait Event들을 이해하고 왜 이러한 Event 들이 발생할 수 밖에 없
는지를 알아내는 것이 보다 중요.
유형 Event 명 Event 설명
Disk I/O Db file Sequential Read 디스크에 Random I/O 수행할 경우 발생.
일반적으로 OLTP 시스템에서 가장 많이 발생
Db file Scattered Read 디스크로 부터 Full Scan을 수행할 경우 발생
자원 경합 Library Cache Latch Library cache 메모리에 접근하기 위해 Latch를 얻을 경우 발생
Library Cache Lock Library cache 내의 특정 Object에 Lock 접근할 때 발생
Log file sync 변경 log buffer 를 log file에 반영하는 동안 발생
Enqueue 주로 Table 자체, 또는 Table Data의 Lock 수행 시 발생
Buffer busy wait Buffer Cache내 동일 블록에 대한 동시 액세스 경합
Latch free 다양한 Shared Memory 영역에 대한 Latch
97. Wait Event Class
Class 명 Class 설명 Wait Event 예
USER I/O User I/O 관련된 다양한 Wait Event Db file sequential read
Db file scattered read
System I/O Background process I/O 와 관련된 Wait Event Db file parallel write
Administrative Index Rebuild와 같은 DBA Command 로 인하여 발생하는 Wait
Event
Alter rbs offline
Concurrency Latch와 같은 Internal Database resource와 관련된 Wait Event Buffer busy wait
Library cache lock
Cluster RAC 의 Resource와 관련된 Wait Event Gc cr block busy
Application 사용자 Application에서 사용된 row level Locking 또는 명확한 Lock
Command 로 인한 Wait Event
Enq:TX – row lock Contention
Wait for Table Lock
Commit Commit 시 발생하는 Redo log write에 관련된 Wait Event Log file sync
Idle 세션이 Inactive 상태에서 Work을 수행 준비하는 단계에서 발생하는
Wait Event
SQL *Net Message form client
Network 네트웍 Messaging시에 발생하는 Wait Event SQL *Net more data to dblink
Other 정상적인 상황에서는 잘 발생하지 않는 Wait Event Wait for EMON to spawn
Configuration Database 또는 Instance 자원의 부적절한 환경 설정 예를 들어 log
file size , shared pool size 를 적절하게 설정하지 못한 경우 발생하
는 Wait Event
Write complete waits
98. DB Time
Database Time은 User process 가 실제 일을 하면서 , 또는 db에서 waiting 되면서 사용된
총 시간을 말함
DB Time = CPU Time + Non Idle Wait Time
Foreground 세션이 DB Call을 하여 자원을
사용한 총 시간
CPU 시간 , I/O 시간 , Non Idle Wait Event 시간
등으로 구성
오라클 성능 측정을 위한 기본 수치
전체 DB Time 중 어떤 유형
의 Wait Event 가 많은 비중
을 차지하고 있는가 ?
DB 시스템의 현재 어떤 자원
을 이용하는데 가장 많은 DB
Time을 사용하고 있는가?
DB가 가장 많이 사용하는 시
스템 자원은 무엇이며 , 성능
상의 병목은 무엇인가?
99. Wait Event로 DB Time 사용현황 모니터링 예제
Wait Event 유형
User I/O 유형의 다양한 Wait Event가 많은 DB
자원을 사용하고 있음.
Wait Event 유형별로 DB Time 사용현황 모니터링
세부 Wait Event 별로 DB Time 사용현황 모니터링
100. AWR(Automatic Workload Repository)
SGA
In-Memory
통계 수집영역
Database
실시간으로 모든 DB 성능 지표를 SGA
In-Memory 통계 영역으로 수집
AWR
스냅샷을 데이터로 보관
MMON
SnapShot
Default
60분
성능 정보에 대한 내장 Repository
Default 60 분마다 데이타베이스 Metrics의 Snapshot을 생성하여 Default 8일간 보관
모든 Oracle 자체 관리기능 ( Self Management) 의 기본 자료가 됨.
( ADDM , SQL Tuning Advisor , Undo Adviser , Segment Adviser )
SYSAUX 테이블스페이스에 보관
AWR은 오라클의 자동화 기능을 강화하기 위해 Oracle 10g 부터
도입된 성능 Metric 자동 수집 Repository임.
오라클 9i버전은 Statspack을 이용하여 유사하게 성능정보 수집
101. AWR 의 작동
13:00 14:00
13:00 시점의 DB의
모든 성능 Metric 정
보를 Snap기록
14:00 시점의 DB의
모든 성능 Metric 정
보를 Snap기록
13시와 14시간의 성능 Metric 정보의 Delta( 증감 값) 으로 다양한 성
능 지표에 대한 정보를 제공
Physical reads : 10,000,000 Physical reads : 15,000,000
13시에 Physical reads가 천만 , 14시에 Physical Reads가 천오백만 이면 한 시간동안에 약 5백만 블록을
physical read 했다는 것이며 초당 1,388 블록 ( 5백만/3600초) physical reads 수행
생성된 AWR Snapshot을 이용하여 어느 시간 구간에서도 성능 분석이 가능함( 시간,일,주,월)
102. AWR Report 항목
Report Summary
Wait Event Statistics
SQL Statistics
Instance Activity Statistics
IO Stats
Buffer Pools Statistics
Advisory Statistics
Wait Statistics
Undo Statistics
Segment Statistics
Dictionary Cache Statistics
Library Cache Statistics
Memory Statistics
AWR Report 의 다양한 항목
103. AWR Report 항목 계층별 구성
Report Summary
Wait Event Statistics SQL Statistics
Instance Activity
Statistics
IO Stats
Buffer Pools
Statistics
Advisory Statistics
Wait Statistics Undo Statistics
Segment
Statistics
Dictionary Cache
Statistics
Library Cache
Statistics
Memory Statistics
성능 지표의 가장 핵심 사항을 요약한 내용
Report Summary 만으로도 주요 성능 이슈가 어떤 것인지 알 수 있음.
Report Summary에서 보다 상세하게 특정 Wait Event
나 Instance Activity 분석이 필요한 경우에 참조
SGA 및 PGA , UNDO, Segment 등
에 대해서 SIZE 조정이나 Re-Org등
의 다양한 튜닝 변경 사항 값들을
적용하여 최적의 셋팅값이 무엇인
지 Advice
다양한 각도로 TOP-N SQL 정보를
제공
수행시간 / Buffer Cache Access 량
/ 디스크 Access 량
Instance Activity Statistics, Advisory statistics에서 보다 상세한 정보가 필요할 경우 참조.
테이블스페이스 , Datafile 별 I/O 의 Read/Write 속도 정보를 제공.
104. AWR Report 활용 방법론 - 예제
DB에 얼마나 많은 User들이 DB Call
을 하여 얼마나 많은 Logical (Memory)
Reads/Write , Physical(Disk)
Reads/Write, Transaction 등을 알 수
있는 수치 제공
Load Profile
부하가 Heavy 한 시스템인가 ? 그렇지
않은 시스템인가? 판단의 근거 제공
DB의 Top 5 Wait Event 정보를 제공
각 Wait Event의 사용 % , 총 시간 , 평균
시간 등의 수치 제공
Top 5 Wait Events
어떠한 Wait Event가 시스템 성능에
가장 큰 영향을 주고 있는지 파악하여
성능 향상을 위해서 어떠한 요소를 개
선해야 할지 파악 가능
어떠한 SQL 이 어느 정도의 I/O 자원을 사
용하는지 수행시간은 얼마나 걸리는지에
대한 정보 제공
수행시간 / Buffer Cache Access 량 / 디
스크 Access 량에 따른 TOP-N 제공
SQL Statistics
Wait Event가 I/O 관련일 경우 Buffer
Cache 또는 Disk I/O 를 과다 사용하
는 SQL 대한 추적 분석 및 튜닝 수행
OS 성능 지표와 결합되면 더욱 효율적 분석 가능
Report Summary
105. AWR Report 분석 예제 – Load Profile & Wait
Load Profile
Top 5 Timed Events
현 시스템은 Logical I/O, Physical I/O의 사용량이
많은 시스템 인가 ?
시스템의 H/W 등을 감안할 때 Physical read의 량은
상당수준 높은 편이며 특히 Logical Reads가 매우 많
음. 이를 감안할 때 자주 수행되는 SQL이 많은 Block을
Access하여 사용됨을 알 수 있음.
DB Wait Event 분석 결과 성능상의 이슈는 무엇
인가?
Random I/O 시 발생하는 DB file sequential read가
일정 수준이상 존재함. Random I/O에 대한 보강 필요.
Log file sync 가 상당수준 이상으로 SQL 수행 성능에
영향을 미치고 있음.
106. Buffer
Gets
수행
횟수
Gets Per
Exec
%
Total
CPU
Time
(s)
Elapsed
Time(s)
SQL
132,136,479 14,535 9,090.9 14.7 2329.05 3830.50 SELECT /*+ index (BA003DM S2_BA003DM) */ brk_cd,
dcl_year, sbm_srl_no, ditc, nvl(clr_mngt_cd, '*') clr_mngt_cd
FROM BA003DM WHERE imp_dcl_sts_cd = 'B' AND
imp_dcl_date <= TO_CHAR(SYSDATE,'YYYYMMDD') AND
(length(txpr_bmen_no) <> 10 OR txpr_bmen_no like 'F%')
AND rownum = 1
57,126,766 20,417 2,798.0 6.4 334.53 419.82 SELECT app_year, app_quat FROM bg072dm WHERE
rownum = 1
39,544,033 30 1,318,134.4 4.4 168.63 237.33 select /*+ index(a S5_CC087DM) */ nvl(max('Y'), 'N') as
gubun
from cc087dm a where a.prn_no in (
select prn_reg_no
from ba304dm where brk_cd = :1)
SQL Order by Gets (Gets는 성능지표에서 Buffer Cache Access Block 수를 의미)
Buffer Cache Access TOP-N SQL
(현 예제는 2시간 동안 지표임)
자주 사용되는 SQL 들이 매우 많은 Buffer Cache를 차지하고 있으므로 상대적으로 다른 SQL들이 Buffer Cache를 사용할
확률이 적어지며 이로 인해 전반적인 SQL의 수행속도가 저하됨.
자주 호출되지는 않는 특정 SQL도 매우 많은 Buffer Cache를 사용하고 있으므로 이들 SQL에 대한 튜닝 필요.
AWR Report 분석 예제 – SQL Statistics
107. AWR Report 분석 예제 - Advisory Statistics
PGA Memory Advisory
현 PGA 메모리 크기를 기준으로 Size를
늘리거나 줄였을 때의 메모리 Hit 영향도
를 비교하여 나타냄
108. ADDM(Automatic Database Diagnostic Monitor)
AWR
ADDM 결과 보관
SnapShot
ADDM
각 AWR 스냅샷 생성 후마다 실행
Instance 를 모니터하여 병목 지점을 감지
AWR에 결과를 저장
• Resource 병목 지점
• 부실한 Oracle Net 연결관리
• Lock 경합
• I/O 영향
• SGA,PGA 메모리 권장
• 로드량이 많은 SQL
• 기타 다수
사용자가 AWR Report 또는 다양한 모니터링 툴을 통해 시스템의 문제점을
분석하지 않아도 오라클이 자동으로 어떠한 문제점이 존재하는 지 분석
109. ADDM 활용 예제
개선이 된다면 약 12% 성능향상 임팩트
자주 사용되는 SQL의 Hard Parsing으로 인해
많은 DB Time을 소모
상기 SQL이 7862번 ( 8시간 동안) Hard Parsing 됨
Application에서 Bind 변수를 사용하거나
Cursor_sharing 파라미터를 force로 설정할
것을 Advice
해당 원인을 찾아내게 된 증상에 대해서 기술
Library cache Lock과 Library cache Pin Wait
Event 가 DB Time을 많이 차지함.